
 19/12/2019
19/12/2019  3824
3824


Інтернет-маркетинг
простою мовою
Содержание статьи

Использование сезонности для определения актуальных и трендовых запросов на продвижение
За последние годы SEO сильно изменилось в плане подхода к работе, изменились варианты закупки ссылок, кто-то вообще от них отказался. Изменились подходы к подбору запросов, появилось много автоматизированных сервисов для сбора максимально полного списка семантики для сайта.
Практически все агентства и независимые специалисты предлагают и собирают большую семантику, и в этом есть выгода. Больше запросов – больше шансов вывести какие-то в ТОП и тем самым дать результаты клиенту – зачем он и обратился.
Как собирается большая семантика? Вкратце – расширение структуры, сбор запросов, парсинг подсказок, очистка семантики от мусорных и ненужных запросов. В итоге, получается ядро с целевыми запросами, если бы не одно «НО»! При сборе семантики никто не будет учитывать сезонность и трендовость запросов по-отдельности, может учитываться сезонность в общем, но не по-отдельности, потому что это занимает немало времени.
В этой статье я предложу один из вариантов (я уверен, что многие из вас имеют свои варианты и способы), я повторюсь, это лишь один из вариантов, который поможет в определении полезных и ненужных запросов с точки зрения сезонности, тренда и спроса.
Для начала нужно поставить собранную семантику на замер сезонности в Key Collector, при этом там есть варианты замера по неделям и по месяцам, будем использовать замер по месяцам:

После замера выгружаем полученные данные в файл и получаем множество цифр, с которыми тяжело работать, как на первый взгляд, но это не так.
Все расчеты будем делать в данном файле, для анализа нам еще потребуется точная частотность запросов и его полнота (Частота “!” / Частота), позже будет понятно зачем.
Первый этап – расчет «грубой» динамики
На этом этапе постараемся определить динамику запроса за 2 года (именно за такой период выгружаются данные по сезонности), для этого считаем следующее:
- Среднее значение за первый год нашей выгрузки (у меня он отмечен серым);
- Среднее значение за второй год;
- Динамику по ср. значения.
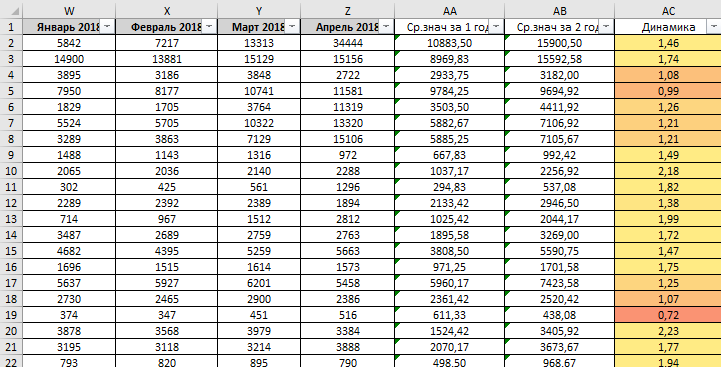
Что мы получаем? А получаем мы понимание того, растет запрос в целом или нет. Для примера возьмем график за 2 года по запросу с динамикой больше 1. Я беру запрос с динамикой 2,18:

А теперь запрос с динамикой меньше 1, в моем случае я возьму запрос с динамикой 0,72:

Разница уже заметна, уже на данном этапе можно сказать, какой запрос стоит использовать, а какой нам не интересен, ведь он теряет свой спрос:
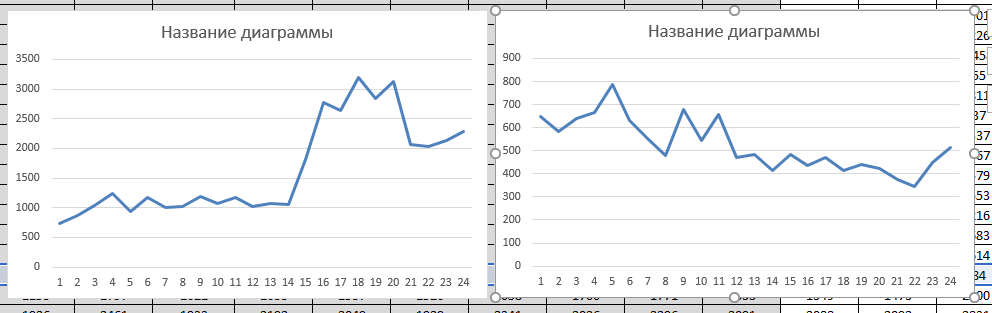
Второй этап
На этом этапе мы считаем сумму частот и динамику по полученным цифрам. Забегу наперед и скажу, что для многих запросов «Динамика по ср. значению» и «Динамика по сумме» будут одинаковые. Итак, посчитали сумму за первый год, сумму частот за второй год и Динамику:

И да, действительно одинаковые цифры, но зачем же тогда нужно было это считать? А вот зачем – сортирую по «Динамике сумм»:

Мы определили запросы, которые только-только начинают свой путь. И они могут быть очень полезными в будущем.
Третий этап
Проделываем первые 2 шага, только уже с максимальной и минимальной частотой в каждом из годов выгрузки. В итоге получаем динамику по максимальным и минимальным точкам графика:
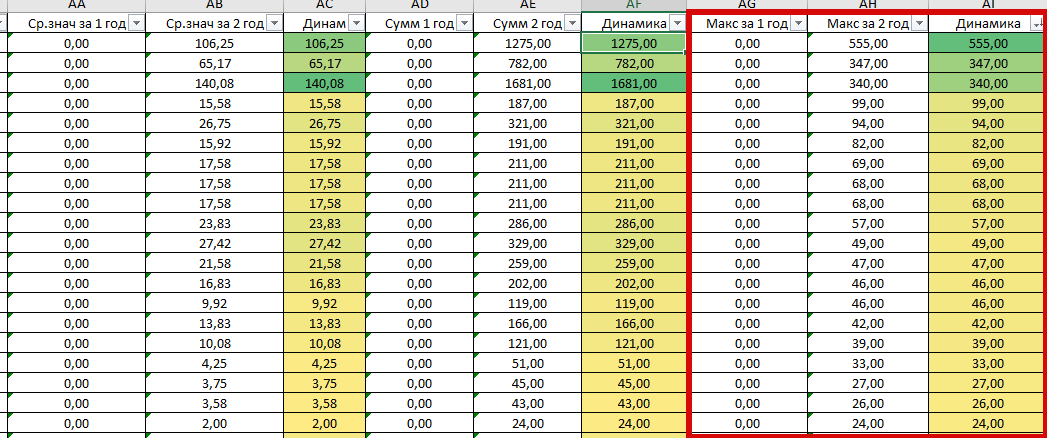

Далее суммируем все данные по динамикам и получаем условный рейтинг запроса по сезонности и спросу:

Если посмотреть на график запросов с наибольшей суммой динамик, то увидим примерно такое – запрос набирает популярность. Скорее всего, в следующем году будет еще популярнее:

А вот если посмотрим на графики запросов с наименьшей суммой, то там мы увидим динамику, которая не будет интересной ни одному специалисту, даже если запрос частотный:

Четвертый этап
Находим запросы, которые будут максимально «безопасными» для нас, то есть запросы, у которых не будет резких скачков до 0 и при этом будет положительная динамика. Назовем эту величину «Нужность», считать ее просто – минимальное значение за 2 год делим на максимальное за 2 год, полученное значение умножаем на суму динамик:
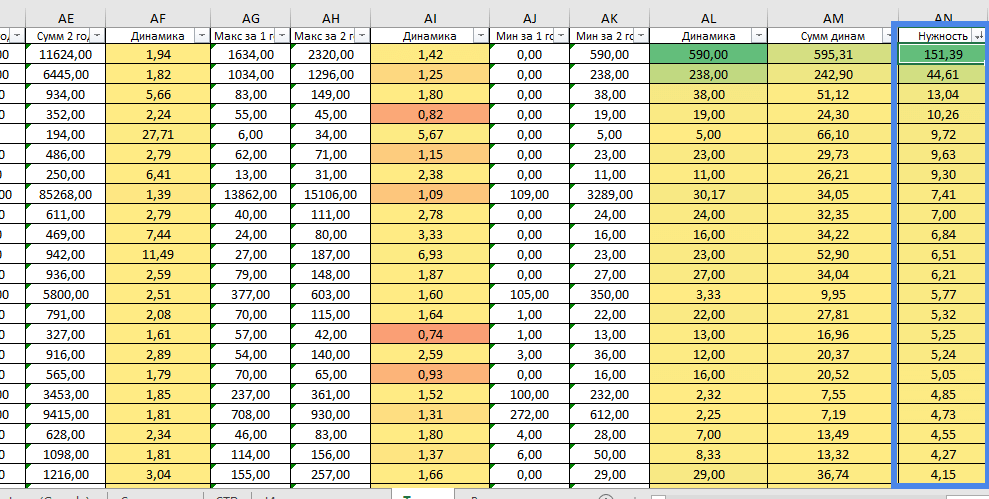
Пятый этап
Так как наша «Нужность» работает не всегда корректно, то нужно исключить такие случаи. Для этого посчитаем следующее значение – Нужность умножим на самую первую динамику по ср. значениям. В итоге получаем такие случаи, когда по «Нужности» запрос имел очень низкий рейтинг, а на самом деле – он для нас полезный. Вот такие запросы наша Поправочная динамика и «подтягивает». Пример:
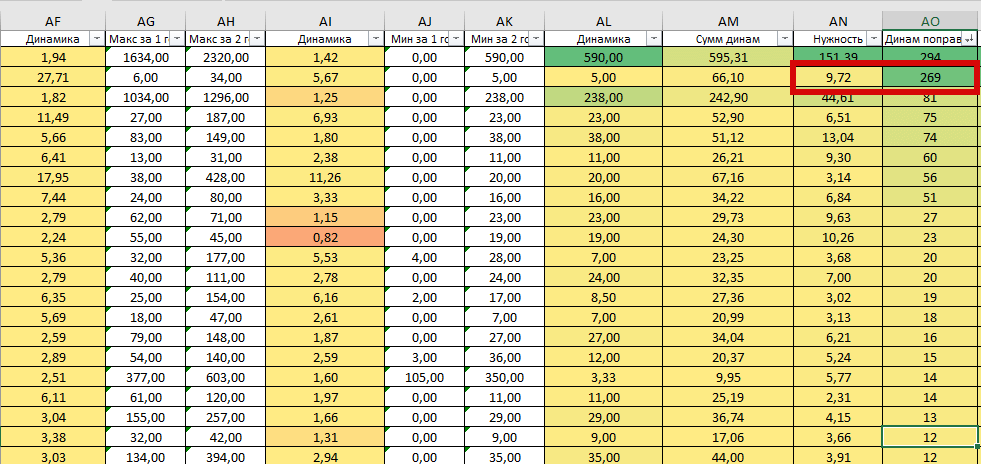
А теперь посмотрим на график запроса. И да, он действительно полезный и нужный:

Шестой этап
Уточним нашу поправочную динамику, для этого значение динамики разделим на ср. значение динамики всех запросов. И далее выведем рейтинг запросов, для этого умножим нашу окончательную динамику на сумму частот за 2 год (нам интересны актуальные запросы), еще умножим все значения на 0,00001, чтобы цифры были более восприимчивыми:


Видим запрос, который вот прямо очень хорош, давайте посмотрим на его график, где мы увидим, что это так и есть:
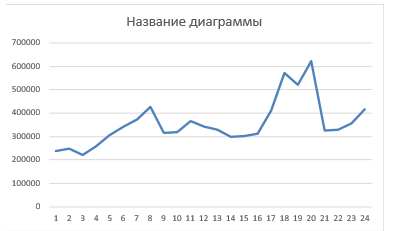
Седьмой этап – финал
Тут нам нужны будут данные, о которых я говорил ранее, а именно:
- Замер точной частоты;
- Полнота.
Для определения финального рейтинга запроса нужно перемножить между собою полученный в шестом этапе рейтинг, точную частоту и полноту:

В итоге мы получим очень полезные запросы вверху (если отсортировать по полученному рейтингу по убыванию) и абсолютно ненужные запросы внизу. Примеры графиков верхних запросов:

А вот какие графики имеют запросы внизу:

Вот как-то так выглядит мой вариант определения полезности запросов. На данный момент это всего лишь бета-версия, и хотелось бы услышать ваше мнение, которое поможет улучшить данный расчет.

коммерческое предложение
Другие статьи автора

29/08/2023
Оптимизация блога (SEO - Search Engine Optimization) состоит из определенных действий, с помощью которых повышается видимость сайта в поисковых системах. А дальше все несложно: улучшается видимость - увеличивается количество посетителей из бесплатного поиска, а затем растет успех блога и, соответственно, всего бизнеса.

10/09/2024
В современном мире, где скорость играет ключевую роль, важно учитывать этот показатель. Низкая скорость загрузки может привести к потере посетителей и снижению позиций в поисковых системах, ведь поисковые алгоритмы учитывают скорость загрузки как важный фактор.

27/08/2024
Маркетинг - это ключевая часть вашего успеха. Независимо от того, это онлайн-магазин одежды или офлайн-точка, вам нужно не только создать привлекательный ассортимент одежды, но и правильно спланировать рекламную кампанию, которая привлечет внимание вашей целевой аудитории.
Последние статьи по #SEO

18/06/2026
Директор по маркетингу — это, прежде всего, топ-менеджер, входящий в состав высшего руководства компании и мыслящий категориями бизнеса, а не отдельных рекламных кампаний.

16/06/2026
Performance-маркетинг — это подход к продвижению, в котором главной целью является не абстрактный охват, а конкретный и измеримый результат.

16/06/2026
Сегодня нейминг — это стратегический инструмент, который напрямую влияет на стоимость привлечения клиента (CAC), конверсию рекламы, юридическую безопасность и, в конечном итоге, на рыночную стоимость компании.