
 11/09/2024
11/09/2024  5673
5673


Інтернет-маркетинг
простою мовою
Содержание статьи

Что такое веб-архив и как он работает?
Веб-архив (или web archive) – это сервис, позволяющий хранить и воспроизводить разные версии веб-страниц за разные периоды времени. Одним из наиболее известных и широко используемых веб-архивов является Web Archive и инструмент Wayback Machine. Этот архив ставит перед собой цель сохранения истории Интернета, обеспечивая доступ к старым версиям веб-сайтов, которые могли быть изменены или удалены.
История создания Web Archive и Wayback Machine
Internet Archive был создан в 1996 году Брюстером Кейлом, американским библиотекарем и предпринимателем. Целью этого проекта является создание цифровой библиотеки, которая будет хранить все знания человечества в свободном доступе. Сервис, запущенный в 2001 году, стал одним из ключевых инструментов Internet Archive, позволяющего просматривать архивированные копии веб-страниц.
Как работает веб-архив?
Веб-архив работает путем регулярного хранения копий веб-страниц с разных сайтов. Эти копии сохраняются в формате, позволяющем пользователям воспроизводить их в будущем. Процесс сохранения веб-страниц может быть автоматическим или инициированным пользователями.
Основные этапы работы веб-архива:
- Сбор контента. Wayback Machine регулярно сканирует Интернет и сохраняет копии доступных веб-страниц. Этот процесс называется «краулинг» (crawling) и включает в себя сохранение HTML-кода страницы, изображений, стилей и других ресурсов, необходимых для ее воспроизведения. Кроме автоматического краулинга, пользователи также могут вручную добавлять страницы в архив, используя инструмент «Save Page Now».
- Сохранность и индексация. После того, как страница была собрана, она сохраняется на серверах Internet Archive. Страница получает уникальный URL-адрес в формате web.archive.org, где пользователи могут просматривать сохраненные копии веб-страниц за конкретные даты.
- Воспроизведение страниц. Когда пользователь вводит URL в поисковую строку Wayback Machine, архив показывает доступные версии этой страницы. Пользователи могут выбирать дату и просматривать, как выглядела страница на тот момент. Воспроизведение происходит максимально приближенно к оригинальному виду с учетом сохраненных стилей, изображений и других ресурсов.
Практическое использование веб-архива
Одним из ключевых аспектов использования веб-архива является возможность оценить изменения в дизайне, структуре и контенте сайта, что помогает понять его эволюцию. Это полезно как для анализа соперников, так и для оптимизации собственных ресурсов. Исследование предыдущих версий ресурсов позволяет выявить эффективные ранее используемые стратегии.
Восстановление утраченного контента через веб-архив
Другой важной функцией web archive является возможность восстановления утраченного контента. В ситуациях, когда сайт был взломан, или его страницы были случайно удалены, веб-архив становится источником для восстановления необходимой информации. Это особенно полезно для блогов, интернет-магазинов или информационных ресурсов, где старый контент может быть все еще актуален для аудитории. С помощью веб-архива можно найти и восстановить статьи, описание товаров или другие ценные материалы.
Анализ истории домена (history) перед покупкой
Перед покупкой нового домена важно провести детальный анализ его истории. Используя web archive, можно узнать, как использовался в прошлом домен: какую тематику он имел, не был ли связан с сомнительными практиками или спамом. Такой анализ помогает избежать рисков, связанных с приобретением домена, что может иметь негативную репутацию или историю, которая повлияет на его SEO-показатели.
Для начала работы с инструментом сначала нужно перейти по ссылке –https://web.archive.org/. Это главная страница веб-архива.
Чтобы просмотреть архивные данные определенного сайта, его url-адрес нужно ввести в поисковую строку.
Что увидеть на изображении:
- Адрес веб-сайта. На экране введен адрес «https://wedex.com.ua/» в поисковую строку Wayback Machine.
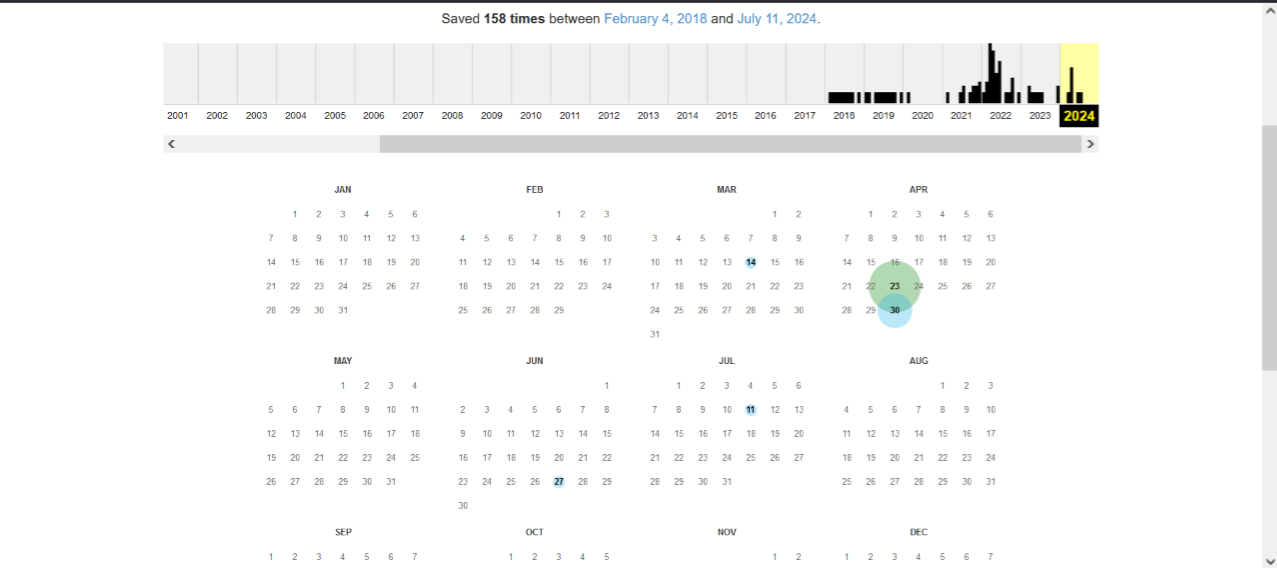
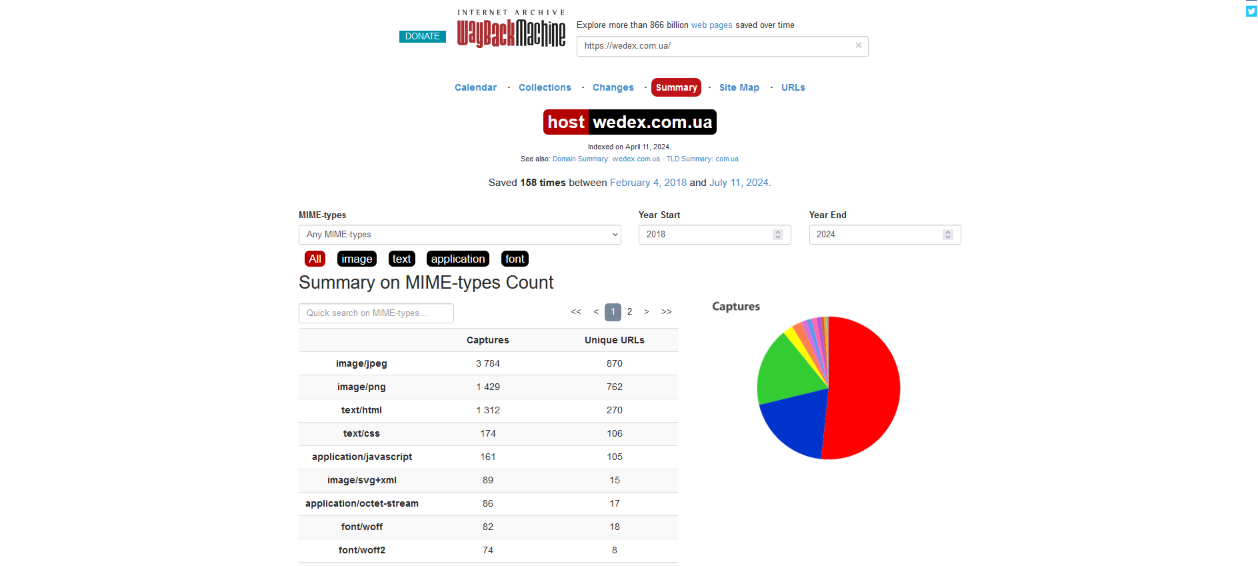
- Количество сохраненных версий. На площадке сохранено 158 версий между 4 февраля 2018 и 11 июля 2024 года.
- График архивации. Верхняя часть изображения показывает график, в котором отображены годы с 2001 по 2024 год. В этом графике можно увидеть количество сохраненных версий за каждый год. Больше всего активных сбережений было в период с 2021 по 2024 годы.
- Календарь. Ниже представлен календарь на 2024 год, где можно увидеть, на какие конкретные даты сохранялись версии сайта. К примеру, он сохранялся 11 июля 2024 года, 30 апреля 2024 года и в другие даты.
Наверное, вы задаетесь вопросом: что это за цветные круги на цифрах и почему у них разные размеры? Эти «круги» другим словом можно назвать «маркеры». Они отмечены одним из четырех цветов:
- синий цвет указывает на то, что вебкраулер получил ответ с кодом 200 OK, то есть ресурс работал стабильно;
- зеленый цвет свидетельствует о коде 3xx – при создании копии на сайте был настроен редирект;
- оранжевый и красный цвета сигнализируют о том, что веб-ресурс был недоступен, и вебкраулер получил код ошибки 4xx или 5xx.
Размер круга зависит от количества запросов работа веб-архива к странице в этот день. Чем больше круг, тем больше копий было создано веб-краулером.
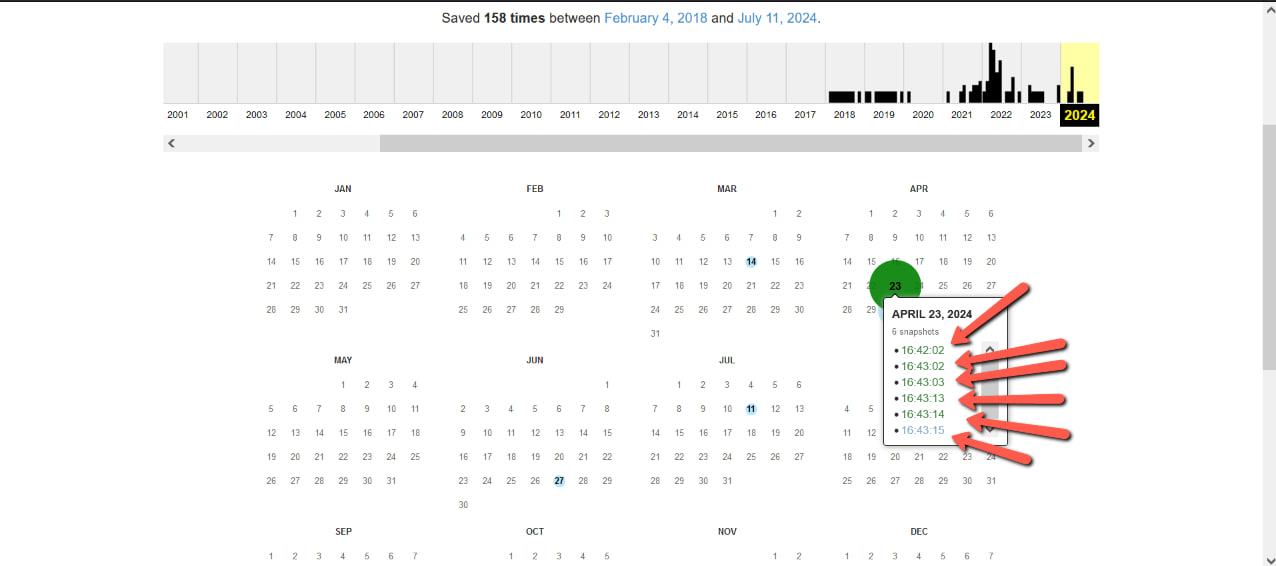
Допустим, вы хотите посмотреть архив веб-страницы за 23 апреля 2024 года. Просто наведите мышкой на это число и выберите нужную версию из списка.
Кроме ссылки, в поисковой строке можно писать ключевое слово – тогда вы сможете получить список продвигаемых по нему сайтов.
Как еще можно работать с веб-архивом
У этого сервиса есть еще несколько дополнительных функций. Чтобы получить к ним доступ, просто нажмите на то, что вам нужно.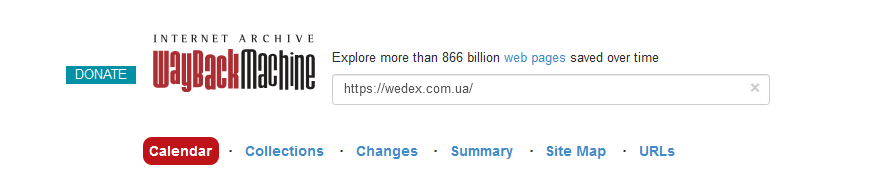
Collections (Коллекции):
- эта вкладка предоставляет доступ к различным тематическим коллекциям, собранным в Internet Archive. Они могут включать архивы определенных веб-сайтов, собрание материалов, документы, мультимедиа и другие типы цифрового контента.
Changes (Изменения):
- вкладка «Изменения» показывает, какие изменения были зафиксированы на портале в течение времени. Здесь можно увидеть сравнение различных версий веб-страниц и понять, какие элементы на странице менялись. Чтобы увидеть сравнение, нужно выбрать снимки сайта за нужный вам период и нажать на кнопку «Compare».
Summary (Сводка):
- эта вкладка дает общий обзор истории архивирования площадки. Здесь можно найти общие статистические данные, такие как количество сохраненных копий страницы, активность веб-краулера на сайте и другие важные сведения.
Site Map (Карта сайта):
- эта вкладка предоставляет структурированную карту сохраненного ресурса. Она позволяет увидеть, как организованы страницы на сайте и быстро перейти к нужному разделу или странице.
URLs (URL-адреса):
- вкладка «URL-адреса» показывает список всех сохраненных URL-адресов на заархивированном портале. Это позволяет просмотреть конкретные страницы или ресурсы, сохраненные в архиве.
Как сохранить текущую версию сайта в веб-архиве?
Сохранение текущей версии сайта в web archive является достаточно простым процессом. Для этого необходимо перейти на страницу Internet Wayback Machine и ввести URL веб-сайта, который необходимо сохранить. После этого нажмите кнопку «Save Page Now», и ваша площадка будет добавлена в archive org web. Это позволит сохранить его актуальную версию для будущего использования, что может быть полезно для отслеживания изменений или сохранения важного контента.
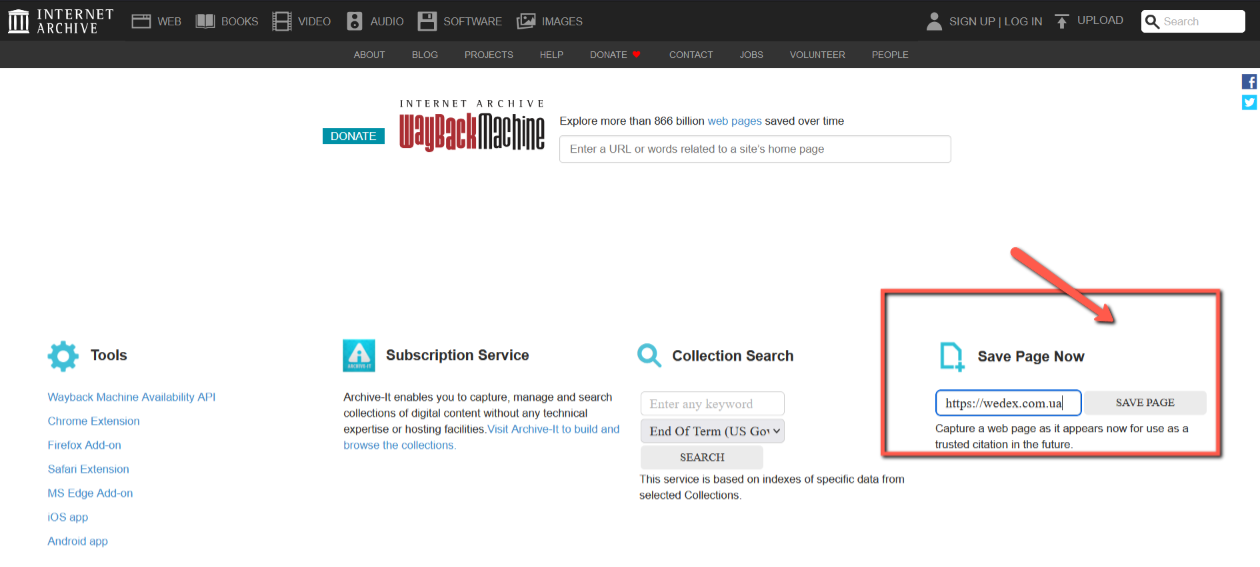
Как запретить добавление сайта в веб-архив?
Если вы:
- беспокоитесь о том, что старые версии ваших веб-страниц могут содержать конфиденциальную информацию, которая не должна быть доступна широкой публике;
- не хотите, чтобы кто-то использовал ваш контент в своих целях;
- хотите удалить личную информацию с открытого доступа – обязательно нужно запретить добавление веб-ресурса.
Существует два способа как это сделать.
Первый – обратиться в его службу поддержки. Если вы обратитесь в службу поддержки, вся имеющаяся информация о вашем сайте будет удалена из интернет-архива, а вебкраулеры не будут сканировать его в будущем.
Для того, чтобы запросить полное удаление вашей площадки из веб-архива, отправьте письмо по адресу info@archive.org, указав в сообщении доменное имя вашего сайта.
Второй – добавить запись в файл robots.txt. Только с этим способом есть один нюанс – файл robots.txt позволяет скрыть контент от вебкраулеров. Это означает, что роботы не будут сканировать ваш сайт и, соответственно, информация не попадет в архив, но существовавший до запрета материал сохранится, и пользователи смогут посмотреть, как ресурс выглядел раньше.
Ниже показан пример запроса для файла robots.txt:
User-agent: ia_archiver
Disallow: /
User-agent: ia_archiver-web.archive.org
Disallow: /
Важно, чтобы файл был в корневом каталоге вашего домена!
Как восстановить сайт из веб-архива?
Восстановление сайта из web archive может быть полезно, если ваш веб-портал был удален или потерял часть контента. Для этого достаточно найти соответствующую версию сайта в Internet Wayback Machine и скопировать нужный контент или структуру вручную. Хотя это не полное восстановление, так как отсутствуют серверные скрипты и базы данных, вы сможете восстановить статический контент и некоторые важные элементы дизайна ресурса. Можно также скопировать контент с помощью скрипта или обратиться в соответствующие службы.
- Ручное копирование
Этот способ требует много времени, потому что веб-архив не имеет функции резервной копии всего сайта. Придется копировать вручную каждую страницу сайта и сохранять в текстовые редакторы. Однако, благодаря этому способу можно сохранить структуру заголовков, изображения и даже базовый стиль страницы. Копировать контент можно с помощью команд Ctrl+C, Ctrl+V или нажать кнопку F12 и копировать программный код.
- Копирование с помощью скриптов
Существуют различные скрипты Python, которые автоматизируют процесс загрузки содержимого с Wayback Machine. Один из популярных скриптов – это wayback-machine-downloader, Wayback Machine Scraper, Wayback Scraper. Чтобы использовать их, нужно сначала установить необходимые инструменты, такие как Python, и установить скрипт через пакетный менеджер (например, pip). В файле README по ссылкам есть пошаговая инструкция по установке и следующим шагам. Это очень поможет оптимизировать время и работу.
- Использование посторонних служб
Эта услуга уже будет платной, потому что придется обратиться в организации или специализированные сайты. Самыми популярными службами являются Archivarix, Wayback Machine Downloader.
Подведем итоги
Web Archive является незаменимым инструментом для сохранения и просмотра исторических версий веб-сайтов. С помощью Internet Wayback Machine можно легко проверить, как изменялась площадка в течение времени, сохранять ее текущую версию или даже восстанавливать утраченные данные. В то же время, если необходимо защитить свой сайт от архивации, существуют методы для запрета добавления его в web archive. Овладение этими навыками поможет эффективно управлять своим ресурсом и обеспечивать сохранение важной цифровой истории.

коммерческое предложение
Другие статьи автора

16/12/2025
Лонгрид — это не формат ради формата. Для бизнеса это инструмент позиционирования, воронки и доверия.

12/01/2026
Преимущества онлайн-методов – это скорость и масштабируемость сбора данных: по сравнению с традиционными подходами они часто дешевле и быстрее.

01/11/2024
Итак, изменение формата рекламы от Google направлено на оптимизацию и расширение возможностей кампаний. Переход к адаптивным поисковым объявлениям обеспечивает большую гибкость, более широкий охват и улучшенный контроль над контентом.
Последние статьи по #SEO

16/02/2025
Соцсети меняются каждый год, и 2025-й не исключение. Мы просмотрели отчет Hootsuite: Social Trends 2025 и собрали для вас самые интересные инсайты.
01/11/2024
Итак, изменение формата рекламы от Google направлено на оптимизацию и расширение возможностей кампаний. Переход к адаптивным поисковым объявлениям обеспечивает большую гибкость, более широкий охват и улучшенный контроль над контентом.

28/10/2024
Ahrefs выпустил углубленный курс с 62 видеоуроками, охватывающими широкий спектр тем SEO и маркетинга. За 3 часа 30 минут вы получите практические знания и навыки работы с инструментами Ahrefs.