
 26/09/2023
26/09/2023  2469
2469


Інтернет-маркетинг
простою мовою
Содержание статьи

Что такое robots.txt и для чего он нужен
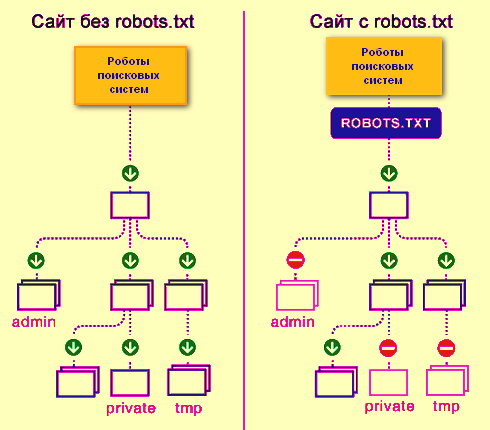
Файл robots.txt – это простой текстовый документ, в котором находятся рекомендации для поисковых роботов всех типов по индексированию вашего сайта – какие страницы и файлы нужно сканировать и добавлять в индекс, а какие нет. Обратите внимание, что именно рекомендации, а не конкретные указания.
Без файла robots.txt поисковые роботы могут проиндексировать все доступные страницы на ресурсе, из-за чего в индексе могут отобразиться дубли, служебные страницы, страницы с результатами поиска по сайту и т. д.
Поскольку это индексный файл (у краулеров прописано его расположение), то находиться он должен в чётко указанном месте – в корневой папке сайта. Открываться должен по такому адресу – http(s)://site.com/robots.txt, где http или https используется в зависимости от того на каком протоколе работает ваш сайт, а вместо site.com необходимо вставлять свой домен. Также обязательным условием должна быть кодировка UTF-8, иначе он просто будет прочитан с ошибками или вовсе проигнорирован.
Совет: чтобы посмотреть свой robots.txt необходимо открыть главную страницу сайта и набрать в адресной строке после нее «/robots.txt».
Примечание: поисковая система Google также регламентирует и размер файла robots – он не должен быть более 500 Кб.
С помощью данного файла можно выполнить следующие действия с вашим сайтом:
- Полностью закрыть его в глазах поисковика
- Открыть все папки и файлы для индексирования
- Ограничить страницы для обхода роботом определёнными правилами.
Ответы сервера при сканировании файла robots.txt
- 2xx – файл найден, и информация получена.
- 3хх – поисковый робот переадресован на другой адрес. Так может происходить не более 5 раз или пока он не получит другой ответ сервера. В ином случае это считается ответом 4ххх.
- 4хх – при таком ответе сервера робот считает, что все содержимое сайта можно сканировать.
- 5хх – данный код говорит о проблемах со стороны сервера, поэтому сканирование запрещается, и робот будет постоянно обращаться на сайт пока не получит отличный от 5хх ответ сервера.
Для чего используется файл robots.txt
Основной его функцией является настройка индексируемости сайта поисковыми краулерами. Обычно его применяют для закрытия от индексации:
- страниц с обработкой заказов, корзин;
- страниц внутреннего поиска по сайту;
- PDF, DOCX и других документов, которые не должны принимать участи в поиске;
- личного кабинета, админ-панелей;
- конфиденциальных файлов и страниц;
- служебных страниц без элементов навигации;
- сторонних скриптов или сервисов.
В случае, если необходимые страницы не будут закрыты от индексации, могут пострадать ваши клиенты (раскроются персональные данные) и Вы (в индекс попадет куча дублей и мусорных страниц, что понизит сайт при ранжировании).
Примечание: страница, закрытая в robots.txt, может также попасть в выдачу, поскольку он является рекомендательным, а не обязательным к исполнению (в особенности это касается Google. В некоторых случаях, страницы нужно закрывать с помощью других способов – тегами meta robots или x-robots.
Оформление файла robots.txt (синтаксис) и директивы
Примечание: команды, применяемые в этом файле, называются директивами.
Все команды в файле оформляются одинаковым образом – сначала следует название директивы и двоеточие (между ними не нужен пробел), далее следует пробел и после него пишется сам параметр. Выглядит это так:
Директива: параметр
Для robots.txt обязательными является всего 2 команды – это User Agent и Disallow, если хоть одна из них отсутствует, то будет выбиваться ошибка при верификации.
Директива User-agent – приветствие для робота
Это первое, что указывается в robots.txt. Данная команда показывает, для какого именно робота пишется данный блок команд. Найдя свое имя, робот будет считывать все команды до следующей директивы user-agent.
User-agent: (и дальше пишется имя того робота, для которого предназначен данный блок директив).
Например, у нас основной робот Google, тогда должно выглядеть так.
User-agent: Googlebot (читается только ботами Google).
Если вам нужно прописать команды для всех роботов сразу, тогда используем символ – *
User-agent: * (читается всеми роботами).
На данный момент есть огромное множество различных ботов. Ниже предоставлен список самых популярных из них на просторах СНГ.
- Googlebot-News — осуществляет поиск новостей;
- Mediapartners-Google — бот сервиса AdSense;
- AdsBot-Google — проверяет качество целевой страницы;
- AdsBot Google Mobile Apps – проверяет качество целевой страницы для приложений на android, аналогично AdsBot;
- Googlebot-Image — для картинок;
- Googlebot-Video — для видео;
- Googlebot-Mobile — для мобильной версии.
Директива Disallow – запрет на индексацию
Данная директива запрещает индексировать файлы и страницы, подпадающие под действие указанного параметра. Синтаксис написания такой же, как и у user-agent.
Например, на сайте есть папка с именем «users» c файлами с пользовательскими данными, и её нужно закрыть от индексации, тогда пишем так:
Disallow: /users/
Таким образом мы закрыли от индексации и папку /users/, и все содержимое в ней.
Примечание: для указания параметров не нужно прописывать сам домен. Например, пишем не «Disallow: site.ru/users/», а «Disallow: /users/».
Директива Allow – разрешение на индексацию
С помощью данной директивы мы можем открывать необходимые для индексации страницы и файлы.
Например, в папке «users» (о ней мы писали выше) есть папка «images», в которой есть картинки необходимые для индексации. Поэтому нам необходимо прописать следующую строку:
Allow: /users/images/
В итоге мы получаем:
User-agent: * Команды указаны для всех краулеров
Disallow: /users/ Закрывает папку «users» и все файлы
Allow: /users/images/ Открывает вложенную папку «images» и все вложенные файлы
Приоретизация указаний
Если есть конфликт между Disallow и Allow, к исполнению будет выбран тот, у которого длинна параметра после двоеточия больше.
Например:
Disallow: /users/
Allow: /users/images/
По сути, первая команда Disallow должна закрыть и папку «images» тоже, но поскольку после двоеточия у первой директивы 7 символов, а у второй 14 символов, то приоритетной будет директива Allow.
В случае, если директивы полностью одинаковые, то приоритет будет отдан той, которая находится ниже. Например, при использовании такой последовательности папка «users» будет открыта:
Disallow: /users/
Allow: /users/
Директива Sitemap (указание карты сайта) или какие страницы важны к индексации
Данная директива показывает, где находится и как называется файл со списком всех url страниц сайтов, которые необходимо добавить в индекс. Также при правильной генерации карты сайта робот сможет четко понимать приоритетность страниц, дату их последнего обновления и добавления.
Директива Sitemap — межсекционная. Она может находиться в любом месте файла robots.txt и не относится к определенной секции User-agent.
Sitemap: http://site.ua/sitemap.xml
В данной директиве путь к файлу карты сайта должен указываться полностью вместе с протоколом и при этом не важно – это http или https.
Если в файле нет директивы Sitemap, краулинговый робот по умолчанию ищет в корневой папке сайта (корне) файл с названием sitemap.xml, если его нет, то страницы на сайте проходятся рандомно, учитывая директивы в роботсе.
Директива Host – указание главного зеркала
Зачастую любой сайт открывается по двум URL-адресам. Первый – blog.ua. Второй – www.blog.ua. В подобных ситуациях нужно определить основное зеркало и сообщить о нем поисковым роботам.
Для этого используется директива Host. Указывается она в конце списке (перед директивой sitemap):
Host: blog.ua
В этом случае роботы видят, что главное зеркало – это URL-адрес без приставки www. И даже, если пользователи будут вводить адрес с ней, то их автоматически перекинет на главное зеркало.
Нужно учитывать, что для Google (и ряда других поисковиков) директива не прописывается – ему сообщать о главном зеркале необходимо в личном кабинете Google Search Console.
Crawl-delay – «ручник» для робота
С помощью данной директивы мы можем ограничивать время между обращениями робота к сайту в течение одного сеанса. Сделано это специально для сайтов, которые работают на очень слабых серверах, и при заходе индексирующего робота ресурс начинает зависать или вовсе отдает 5хх ответ сервера.
Синтаксис написания выглядит так:
Crawl-delay: 3
где 3 – это время в секундах между обращениями бота к сайту.
Сами поисковые системы рекомендуют использовать данную директиву только в крайних случаях.
Специальные символы *, $, #
Для упрощения составления файла и для ускорения интерпретации машинами информации из файла используются специальные символы.
Первый и самый важный символ – это * (звездочка)
Она означает, что вместо нее можно подставить любое количество любых символов.
В общем понимании это выглядит так:
1*1=121, 1*1=1234567891 и т.д.
Как это применить в нашем случае?
Например, у нас есть такие страницы:
site.ua/catalog/123
site.ua/catalog/111
site.ua/catalog/12
site.ua/catalog/23
site.ua/catalog/231
site.ua/catalog/2789
И нам нужно закрыть от индексации site.ua/catalog/123, site.ua/catalog/111, site.ua/catalog/12, но при этом не закрыть site.ua/catalog/23, site.ua/catalog/231, site.ua/catalog/2789.
Можно, конечно, сделать так:
User-agent: *
Disallow: /catalog/123
Disallow: /catalog/111
Disallow: /catalog/12
Но в 2 раза короче будет так:
User-agent: *
Disallow: /catalog/1*
Также это можно использовать для открытия всех файлов одинакового формата в одной папке.
Например, в папке «catalog» лежат файлы с расширением php, rar, pdf и jpg и нам нужно открыть последние, а все закрыть. Сделать это можно так.
Пример:
User-agent: *
Disallow: /catalog/
Allow: /catalog/*.jpg
Важное примечание: в конце любого параметра в директиве робот по умолчанию ставит звездочку. Например, кусок из примера выше краулер видит, как:
User-agent: *
Disallow: /catalog/*
Allow: /catalog/*.jpg*
Не забывайте об этом.
Стоп строка или знак «доллара» – $
Символ $ означает окончание строки – он отменяет звездочку в конце параметра. Как это понимает робот. У нас есть в папке «catalog» 2 типа файлов с расширением jpg и jp, и нам нужно открыть к индексации вторые, но запретить первые. Сделать это можно так:
User-agent: *
Disallow: /catalog/
Allow: /catalog/*.jp$
Если бы $ там не было, тогда индексировались бы все файлы, не только с jp
Немного поэзии с #
Обычно знак «решетка» в файле robots.txt используется для добавления комментариев. Робот не читает символы, стоящие от этого символа, справа и сразу переходит на следующую строку.
User-agent: *
#Открыл данный блок директив для всех роботов
Disallow: /catalog/
#Закрыл от индексации папку catalog
Allow: /catalog/*.jp$
#Открыл для индексации файлы с расширением jp
Поэтому комментарии НЕЛЬЗЯ размещать слева от директив в одной строке.
#Открыл для индексации файлы с расширением jp Allow: /catalog/*.jp$
Допускается комменты размещать справа от директивы и параметра.
Allow: /catalog/*.jp$ #Открыл для индексации файлы с расширением jp
Идеальный файл robots.txt
User-agent: * #Есть обязательная директива
Disallow: # Есть обязательная директива
Host: http://site.ua #Указано основное зеркало сайта
Sitemap: http://site.ua/sitemap.xml #Есть ссылка на файл с url всех страниц сайта
Как проверить правильно ли написан файл robots.txt
После того, как файл залит в корневой каталог, нужно о нем сообщить поисковикам. Но перед этим обязательно проверить правильность его написания. Для каждого поисковика инструкция своя. Мы рассмотрим для Google:
- Войти в личный кабинет Google Search Console (заранее добавив туда сайт);
- Зайти в раздел «Сканирование»;
- Выбрать пункт «Инструмент проверки файла»;
- Указать путь к файлу (просто дописать «robots.txt», поскольку URL-адрес веб-ресурса там уже прописан и так).
После проверки поисковик даст знать, есть ли там ошибки. Если есть – нужно исправить, если нет – нажимаете «Отправить». Готово! Гугл знает, что у вас появился файл и скоро его просканирует.
Подведем итоги
Из этого всего следует, что при составлении индексного файла robots.txt нужно быть предельно внимательным, ведь одно неправильное решение и с позициями сайта можно попрощаться, а сайт просто выпадет из выдачи. Ничего сложного в добавлении файла robots.txt на сайт нет, вы легко справитесь, нужно просто уделить время и сделать все на совесть.

коммерческое предложение
Другие статьи автора

24/04/2025
Благодаря концепции SaaS доступ к современным программам, обновлениям application и технической поддержке сайтов стал проще, что позволило ускорить процесс внедрения инновационных решений на рынке Украины и за ее пределами.

08/10/2018
В 90% случаев предприниматель, решивший развивать свой бизнес онлайн, сталкивается с небольшой проблемой при выборе подрядчика для его раскрутки. Сейчас я предлагаю вам рассмотреть три возможных варианта выбора лиц, которые будут отвечать за развитие вашего сайта, а именно работать с частным фрилансером, маркетинговым агентством или пригласить специалиста в офис.

29/09/2023
Рекламный сервис Google Adwords (Ads) - это система для настройки и размещения контекстной рекламы в поисковой системе, на сайтах Google и на партнерских ресурсах в контекстно-медийной сети. А еще это первый в мире сервис, по количеству рекламодателей и потребителей контекстной рекламы (поисковой, медийной, товарной).
Последние статьи по #SEO

05/03/2025
Merchant Center - это ключевой инструмент для размещения мерчант рекламы в Google, который помогает интегрировать товары с платформой Google Merchant Center и обеспечивать прозрачность информации о покупках.

05/03/2025
Рекламный кабинет Гугл Ads является одним из ключевых инструментов для запуска рекламы в интернете. Однако многие пользователи, запускающие рекламу Google, и специалисты по таргетингу сталкиваются с проблемой блокировки учетной записи.

19/11/2024
Менеджер по контекстной рекламе является специалистом, который настраивает рекламные кампании, оплата за которые начисляется за клики по рекламным объявлениям, которые были осуществлены потенциальными клиентами. Ключевая задача PPC-специалиста - повышать эффективность рекламы и оптимизировать ее так, чтобы клиент получил как можно больше трафика на сайт за оптимальную цену и мог больше зарабатывать.