
 26/09/2023
26/09/2023  3965
3965


Інтернет-маркетинг
простою мовою
Зміст статті

Що таке robots.txt і для чого він потрібний
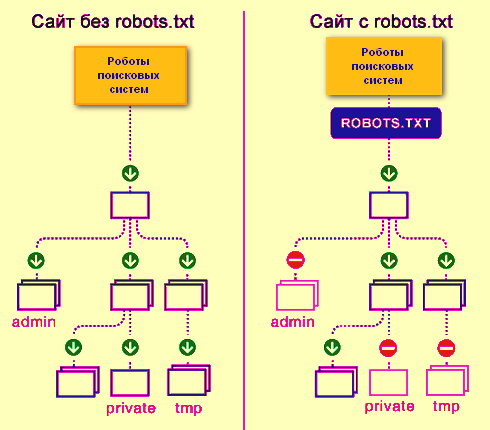
Файл robots.txt – це простий текстовий документ, в якому містяться рекомендації для пошукових роботів всіх типів щодо індексування вашого сайту – які сторінки та файли потрібно сканувати та додавати до індексу, а які ні. Зауважте, що саме рекомендації, а не конкретні вказівки.
Без файлу robots.txt пошукові роботи можуть проіндексувати всі доступні сторінки на ресурсі, через що в індексі можуть відобразитись дублі, службові сторінки, сторінки з результатами пошуку по сайту і т.д.
Оскільки це індексний файл (у краулерів прописано його розташування), то він повинен перебувати в чітко вказаному місці – у кореневій папці сайту. Відкриватися має за такою адресою – http(s)://site.com/robots.txt, де http або https використовується залежно від того, на якому протоколі працює ваш сайт, а замість site.com необхідно вставляти свій домен. Також обов’язковою умовою має бути кодування UTF-8, інакше його просто прочитають з помилками або зовсім проігнорують.
Порада: щоб переглянути свій robots.txt необхідно відкрити головну сторінку сайту та набрати в адресному рядку після неї «/robots.txt».
Примітка: пошукова система Google також регламентує розмір файлу robots – він не повинен бути більше 500 Кб.
За допомогою цього файлу можна виконати такі дії з вашим сайтом:
- Повністю закрити його в очах пошукача
- Відкрити всі папки та файли для індексування
- Обмежити сторінки для обходу роботом певними правилами.
Відповіді сервера під час сканування файлу robots.txt
- 2xx – файл знайдено, та інформація отримана.
- 3хх – пошуковий робот переадресований на іншу адресу. Так може відбуватися не більше 5 разів або доки він не отримає іншу відповідь сервера. В іншому випадку це вважається відповіддю 4ххх.
- 4хх – за такої відповіді сервера робот вважає, що весь вміст сайту можна сканувати.
- 5хх – цей код говорить про проблеми з боку сервера, тому сканування забороняється, і робот постійно звертатися на сайт поки не отримає відмінну від 5хх відповідь сервера.
Для чого використовується файл robots.txt
Основною його функцією є настроювання індексованості сайту пошуковими краулерами. Зазвичай його застосовують для закриття від індексації:
- сторінок із обробкою замовлень, кошиків;
- сторінок внутрішнього пошуку на сайті;
- PDF, DOCX та інших документів, які не повинні брати участь у пошуку;
- особистого кабінету, адмін-панелей;
- конфіденційних файлів та сторінок;
- службових сторінок без елементів навігації;
- сторонніх скриптів чи сервісів.
У випадку, якщо необхідні сторінки не будуть закриті від індексації, можуть постраждати ваші клієнти (розкриються персональні дані) і Ви (в індекс потрапить купа дублів та сторінок для сміття, що понизить сайт при ранжируванні).
Примітка: сторінка, закрита в robots.txt, може також потрапити у видачу, оскільки він є рекомендаційним, а не обов’язковим до виконання (особливо це стосується Google. У деяких випадках, сторінки потрібно закривати за допомогою інших способів – тегами meta robots або x-robots.
Оформлення файлу robots.txt (синтаксис) та директиви
Примітка: команди, які використовуються у цьому файлі, називаються директивами.
Всі команди у файлі оформляються однаковим чином – спочатку слід назва директиви і двокрапка (між ними не потрібен пробіл), далі слідує пробіл і після нього пишеться сам параметр. Виглядає це так:
Директива: параметр
Для robots.txt обов’язковими є лише 2 команди – це User Agent та Disallow, якщо хоч одна з них відсутня, то вибиватиметься помилка при верифікації.
Директива User-agent – привітання для робота
Це перше, що вказується у robots.txt. Ця команда показує, для якого робота пишеться даний блок команд. Знайшовши своє ім’я, робот зчитуватиме всі команди до наступної директиви user-agent.
User-agent: (далі пишеться ім’я того робота, для якого призначений даний блок директив).
Наприклад, у нас основний робот Google, тоді має виглядати так.
User-agent: Googlebot (читається лише ботами Google).
Якщо вам потрібно прописати команди для всіх роботів відразу, тоді використовуємо символ *
User-agent: * (читається усіма роботами).
На даний момент є безліч різних роботів. Нижче надано список найпопулярніших із них на просторах СНД.
- Googlebot-News – здійснює пошук новин;
- Mediapartners-Google – бот сервісу AdSense;
- AdsBot-Google – перевіряє якість цільової сторінки;
- AdsBot Google Mobile Apps – перевіряє якість цільової сторінки для додатків на Android, аналогічно AdsBot;
- Googlebot-Image – для картинок;
- Googlebot-Video – для відео;
- Googlebot-Mobile – для мобільної версії.
Директива Disallow – заборона індексації
Ця директива забороняє індексувати файли та сторінки, які підпадають під дію вказаного параметра. Синтаксис написання такий самий, як і у user-agent.
Наприклад, на сайті є папка з ім’ям «users» c файлами з даними користувача, і її потрібно закрити від індексації, тоді пишемо так:
Disallow: /users/
Таким чином ми закрили від індексації та папку /users/, і весь вміст у ній.
Примітка: для вказівки параметрів не потрібно прописувати сам домен. Наприклад, пишемо не Disallow: site.ru/users/, а Disallow: /users/.
Директива Allow – дозвіл на індексацію
За допомогою цієї директиви ми можемо відкривати необхідні для індексації сторінки та файли.
Наприклад, у папці “users” (про неї ми писали вище) є папка “images”, в якій є зображення необхідні для індексації. Тому нам необхідно прописати наступний рядок:
Allow: /users/images/
У результаті ми отримуємо:
User-agent: * Команди вказані для всіх краулерів
Disallow: /users/ Закриває папку «users» та всі файли
Allow: /users/images/ Відкриває вкладену папку “images” і всі вкладені файли
Пріоретизація вказівок
Якщо є конфлікт між Disallow та Allow, до виконання буде обраний той, у якого довжина параметра після двокрапки більша.
Наприклад:
Disallow: /users/
Allow: /users/images/
По суті, перша команда Disallow має закрити і папку «images» теж, але оскільки після двокрапки у першої директиви 7 символів, а у другої 14 символів, то пріоритетною буде директива Allow.
У випадку, якщо директиви повністю однакові, то пріоритет буде відданий нижче. Наприклад, при використанні такої послідовності папка «users» буде відкрита:
Disallow: /users/
Allow: /users/
Директива Sitemap (вказівка картки сайту) або які сторінки важливі для індексації
Ця директива показує, де знаходиться і як називається файл зі списком усіх URL сторінок сайтів, які необхідно додати в індекс. Також при правильній генерації картки сайту робот зможе чітко розуміти пріоритетність сторінок, дату їхнього останнього оновлення та додавання.
Директива Sitemap – міжсекційна. Вона може знаходитись у будь-якому місці файлу robots.txt і не відноситься до певної секції User-agent.
Sitemap: http://site.ua/sitemap.xml
У цій директиві шлях до файлу картки сайту повинен вказуватися повністю разом із протоколом і при цьому не важливо – це http або https.
Якщо у файлі немає директиви Sitemap, краулінговий робот за замовчуванням шукає у кореневій папці сайту (корені) файл під назвою sitemap.xml, якщо його немає, то сторінки на сайті проходять рандомно, враховуючи директиви в роботсі.
Директива Host – вказівка головного дзеркала
Найчастіше будь-який сайт відкриваєтьсяза двома URL-адресами. Перший – blog.ua. Другий – www.blog.ua. У подібних ситуаціях потрібно визначити основне дзеркало та повідомити про нього пошукові роботи.
Для цього використовується директива Host. Вказується вона наприкінці списку (перед директивою sitemap):
Host: blog.ua
У цьому випадку роботи бачать, що головне дзеркало – це URL-адреса без приставки www. І навіть якщо користувачі будуть вводити адресу з нею, то їх автоматично перекине на головне дзеркало.
Потрібно враховувати, що для Google (і деяких інших пошуковиків) директива не прописується – йому повідомляти про головне дзеркало необхідно в особистому кабінеті Google Search Console.
Crawl-delay – «ручник» для робота
За допомогою цієї директиви ми можемо обмежувати час між зверненнями робота на сайт протягом одного сеансу. Зроблено це спеціально для сайтів, які працюють на дуже слабких серверах, і при заході індексує робота ресурс починає зависати або віддає 5хх відповідь сервера.
Синтаксис написання виглядає так:
Crawl-delay: 3
де 3 – це час у секундах між зверненнями робота до сайту.
Самі пошукові системи рекомендують використовувати цю директиву лише у крайніх випадках.
Спеціальні символи *, $, #
Для спрощення складання файлу та прискорення інтерпретації машинами інформації з файлу використовуються спеціальні символи.
Перший і найважливіший символ – це * (зірочка)
Вона означає, що замість неї можна підставити будь-яку кількість символів.
У загальному розумінні це виглядає так:
1 * 1 = 121, 1 * 1 = 1234567891 і т.д.
Як це застосувати у нашому випадку?
Наприклад, у нас є такі сторінки:
site.ua/catalog/123
site.ua/catalog/111
site.ua/catalog/12
site.ua/catalog/23
site.ua/catalog/231
site.ua/catalog/2789
І нам потрібно закрити від індексації site.ua/catalog/123, site.ua/catalog/111, site.ua/catalog/12, але при цьому не закрити site.ua/catalog/23, site.ua/catalog/231 , site.ua/catalog/2789.
Можна, звичайно, зробити так:
User-agent: *
Disallow: /catalog/123
Disallow: /catalog/111
Disallow: /catalog/12
Але в 2 рази коротше буде так:
User-agent: *
Disallow: /catalog/1*
Також це можна використовувати для відкриття всіх файлів однакового формату в одній папці.
Наприклад, у папці «catalog» лежать файли з розширенням php, rar, pdf та jpg і нам потрібно відкрити останні, а все закрити. Зробити це можна так.
Приклад:
User-agent: *
Disallow: /catalog/
Allow: /catalog/*.jpg
Важлива примітка: в кінці будь-якого параметра в директиві робот за промовчанням ставить зірочку. Наприклад, шматок з прикладу вище краулер бачить, як:
User-agent: *
Disallow: /catalog/*
Allow: /catalog/*.jpg*
Не забувайте про це.
Стоп рядок або знак “долара” – $
Символ $ означає закінчення рядка – він скасовує зірочку в кінці параметра. Як це розуміє робот? Ми маємо в папці «catalog» 2 типи файлів з розширенням jpg і jp, і нам потрібно відкрити до індексації другі, але заборонити перші. Зробити це можна так:
User-agent: *
Disallow: /catalog/
Allow: /catalog/*.jp$
Якби $ там не було, тоді індексувалися б усі файли, не лише з jp
Трохи поезії з #
Зазвичай знак “решітка” у файлі robots.txt використовується для додавання коментарів. Робот не читає символи, що стоять від цього символу праворуч і відразу переходить на наступний рядок.
User-agent: *
#Відкрив цей блок директив для всіх роботів
Disallow: /catalog/
#Закрив від індексації папку catalog
Allow: /catalog/*.jp$
#Відкрив для індексації файли з розширенням jp
Тому коментарі НЕ МОЖНА розміщувати ліворуч від директив в одному рядку.
#Відкрив для індексації файли з розширенням jpAllow: /catalog/*.jp$
Дозволяється коменти розміщувати праворуч від директиви та параметра.
Allow: /catalog/*.jp$ #Відкрив для індексації файли з розширенням jp
Ідеальний файл robots.txt
User-agent: * #Є обов’язкова директива
Disallow: #Є обов’язкова директива
Host: http://site.ua #Вказано основне дзеркало сайту
Sitemap: http://site.ua/sitemap.xml #Є посилання на файл з url усіх сторінок сайту
Як перевірити чи правильно написаний файл robots.txt
Після того, як файл залитий у кореневий каталог, потрібно про нього повідомити пошукові системи. Але перед цим обов’язково перевірити правильність його написання. Для кожного пошуковика інструкція своя. Ми розглянемо для Google:
- Увійти до особистого кабінету Google Search Console (заздалегідь додавши туди сайт);
- Зайти до розділу «Сканування»;
- Вибрати пункт “Інструмент перевірки файлу”;
- Вказати шлях до файлу (просто дописати “robots.txt”, оскільки URL-адреса веб-ресурсу там уже прописана і так).
Після перевірки пошуковик дасть знати, чи є помилки. Якщо є – потрібно виправити, якщо ні – натискаєте «Надіслати». Готово! Google знає, що у вас з’явився файл і незабаром його просканує.
Підведемо підсумки
З цього слід, що при складанні індексного файлу robots.txt потрібно бути гранично уважним, адже одне неправильне рішення і з позиціями сайту можна попрощатися, а сайт просто випаде з видачі. Нічого складного в додаванні файлу robots.txt на сайт немає, ви легко впораєтеся, потрібно просто приділити час і зробити все на совість.

комерційна пропозиція
Інші статті автора

06/10/2025
Всесвітня організація інтелектуальної власності пояснює: керування комерційною таємницею і системний підхід до її захисту — ключовий елемент бізнес-стратегії в сучасному середовищі.

13/05/2025
З урахуванням можливостей, які надає Prom.ua, не дивно, що велика кількість підприємців розглядають можливість створення інтернет-магазину на базі цього маркетплейсу.

24/04/2025
Завдяки концепції SaaS доступ до сучасних програм, оновлень application і технічної підтримки сайтів став простішим, що дало змогу прискорити процес впровадження інноваційних рішень на ринку України та за її межами.
Останні статті по #SEO

21/01/2026
Доступність веб сайтів перестає бути лише етичним питанням. Тепер це операційний ризик і конкурентна перевага.

06/10/2025
Розуміння структури адмінки та правил доступу сьогодні є критично важливим для власників бізнесу, маркетологів і розробників.

17/06/2025
Пошукові роботи сканують усі наявні в мережі сайти для того, щоб з’ясувати їхню відповідність до конкретної тематики. Коли Google зрозуміє, до якої категорії відноситься веб-ресурс або конкретна сторінку, він почне рекомендувати її користувачам.