
 24/12/2021
24/12/2021  2577
2577


Інтернет-маркетинг
простою мовою
Содержание статьи

XPath в помощь SEO-специалисту: как правильно и быстро парсить конкурентов?
XPath — это такой язык запросов к элементам xml или html документа. Работа XPath-запросов построена на декларативном языке запросов, то есть, чтобы получить нужные данные необходимо всего лишь корректно задать запрос, описывающий эти данные, а все остальное сделает интерпретатор языка XPath. Удобно? А как же, удобно и просто если понимать этот язык. А какие возможности есть у XPath для нас, то есть для SEO-специалистов? Давайте разбираться.
Основные возможности XPath
Какие данные можно спарсить?
- Любую информацию из кода практически с любого сайта. Тут важно понимать, мы можем попасть на сайт с защитой от парсинга. Например, спарсить любой сайт Google не получится. Тоже самое касается и Авито, тоже довольно-таки сложно. Но большую часть сайтов можно успешно спарсить.
- Цены, наличие товаров и предложений, тексты, любые текстовые характеристики, изображения и даже 3D-фото.
- Описание, отзывы, структуру сайта.
- Контактную информацию (например почту), неочевидные свойства и т.д.
Все элементы на странице, которые есть в коде сайта можно успешно выгрузить в Excel.
Какие есть ограничения при парсинге через XPath?
- Бан по user-agent. Некоторые сайты запрещают доступ парсерам у которых в user-agent указано что это программа. Это ограничение можно обойти, если в настройках выставить юзер-агент поисковой системы, например. Для этого переходим в Configuration> User-Agent и выбрать Googlebot.
- Запрет в robots.txt. Для обхода этого запрета нужно перейти в настройки Screaming Frog в Configuration> Robots.txt> Settings и выбирать «Игнорировать robots.txt»
- Бан по IP. Тут есть несколько вариантов решения проблемы: использовать VPN или в настройках снизить скорость парсинга сайта, чтобы не вызывать подозрения и не попасть под ограничения.
Как научиться понимать XPath и составлять запросы правильно?
Первым что необходимо сделать – это изучить базовый синтаксис XPath, в сети много статей на этот случай и достаточное кол-во примеров парсинга различны элементов. Давайте разберем несколько простых примеров, которые помогут вам понять основу языка XPath:
- //h1/text() – Заголовок Н1, именно текст
- //h1[@class=”header”]/text() – Заголовок Н1 с классом header, именно текст
- //span[@class=”new-price”] – Значение элемента span с классом new-price
- //input[@class=”addtocart”]/@title – Текст кнопки с классом addtocart, у которой название состоит в элементе @title
- //a/text() – Получаем текст ссылки
- //a/@href – УРЛ ссылки
- //img/@src – УРЛ изображения
- //div[4]/img/@src – Изображение в 4-м по очередности классе div
Разберем составные запроса XPath на примере //div[@class=”default__button2 center”]/input/@value, этот запрос парсит название кнопки:
Как же это происходит:
- //div – игнорируем все элементы до нужного нам, именно за это отвечает двойной слеш «//». В данном случае мы указали блок, в котором расположено нужную кнопку.
- [@class=”default__button2 center”] – в квадратных скобрах мы указываем отличительную особенность нужного нам элемента, это может быть класс, идентификатор и т.д.
- /input – дальше указываем, собственно, саму кнопку
- /@value – и указываем что нужно вытащить из нее
Если вы используете спайдер, например Screaming Frog Seo Spider, то там есть настройка что именно парсить: весь код или только текстовое значение, если же вы парсите при помощи Гугл таблиц, то нам нужно указать /text(), чтобы спарсился только текст кнопки, без лишнего кода: //div[@class=”default__button2 center”]/input/@value/text() Теперь, когда мы разобрались с базовыми атрибутами языка XPath, давайте на реальных примерах используем полученные знания и спарсим цены и УРЛ изображений товаров.
Пример №1. Парсинг цены
Есть немало вариантов и программ при помощи, которых можно анализировать ценовую политику конкурентов, но половина из них работает непонятно как, вторая половина платная и т.д. Вот здесь на помощь и приходит парсинг цен конкурентов при помощи XPath. Возьмем для примера сайт https://shishastore.com.ua/ . У нас есть вот такая типичная карточка товара, где есть 2 варианта цен – обычная и для заведений.
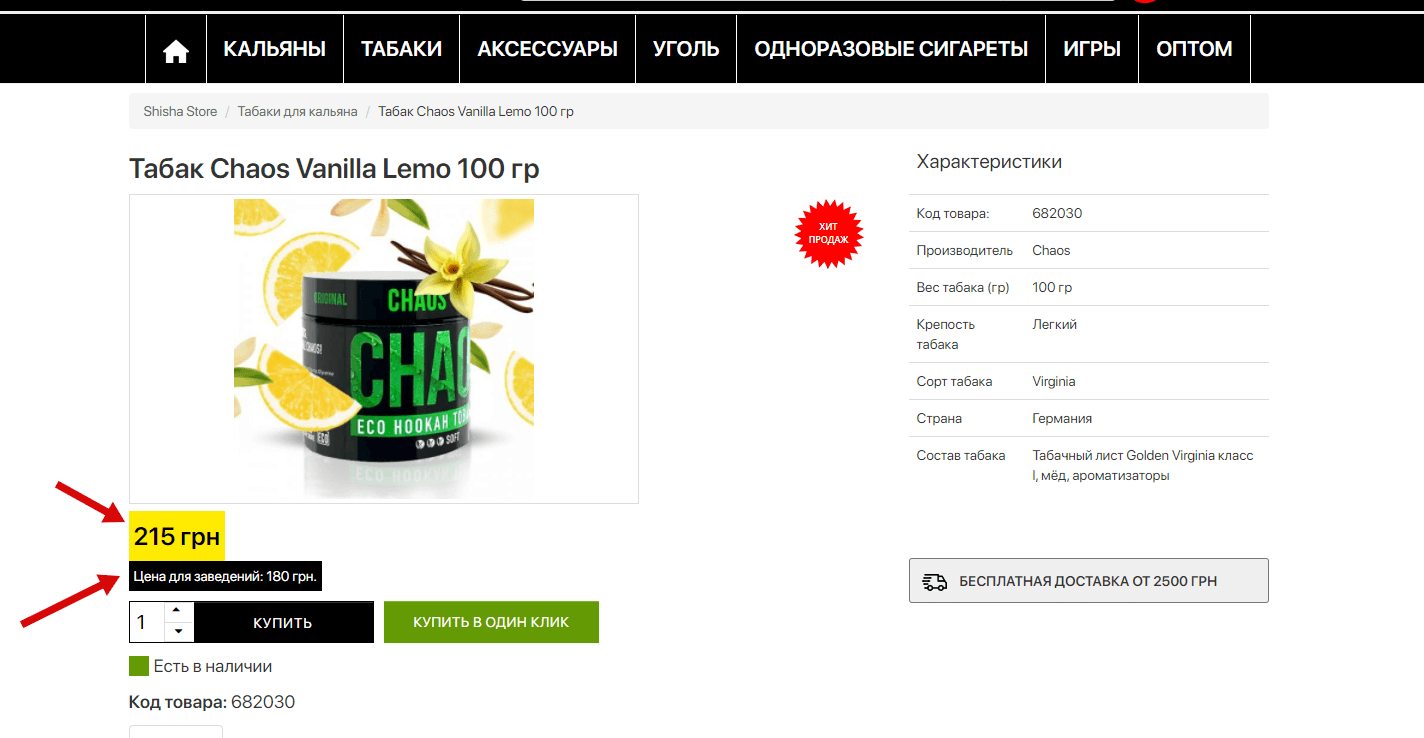
Для начала нам нужно понять в каком теге/классе состоит блок цены в карточке товара. Для этого нужно посмотреть код блока, в Chrome это делается при наведении на нужный элемент и по нажатию на правую кнопку мыши, дальше выбираем «Посмотреть код»:
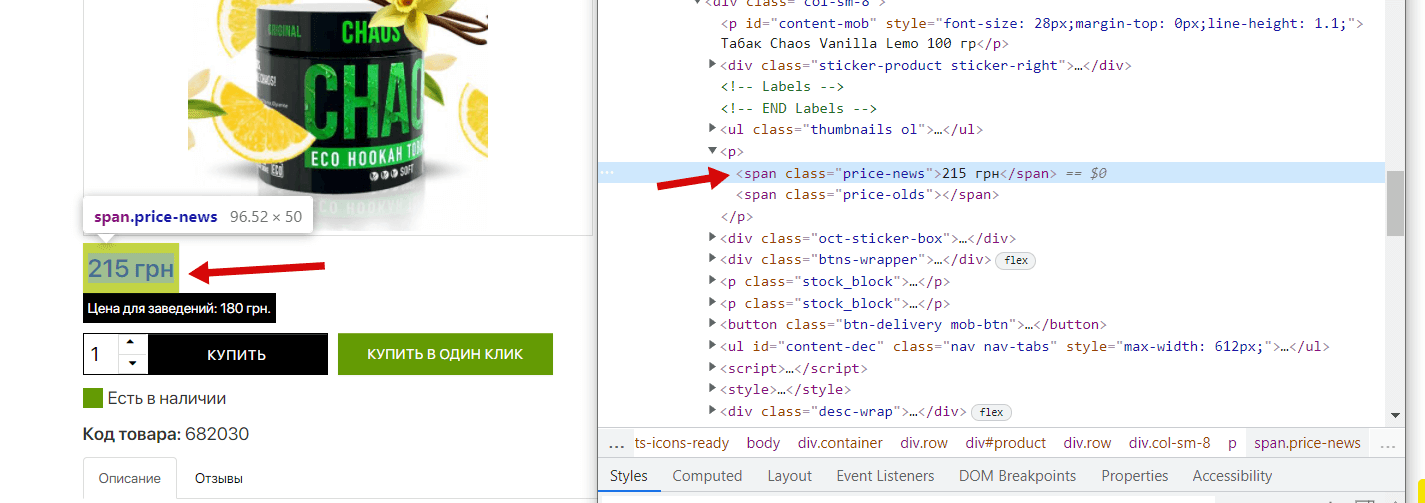
Видим, что цена у нас состоит в теге <span> с классом price-news, вместе с этим замечаем, что есть еще и тег для старой цены (в данном товаре ее нет), его мы тоже спарсим для полноты картины, что покажет нам на какие товары и какие скидки делает конкурент. Теперь нам нужно аналогично узнать данные для блока «Цена для заведений», повторяем действия:
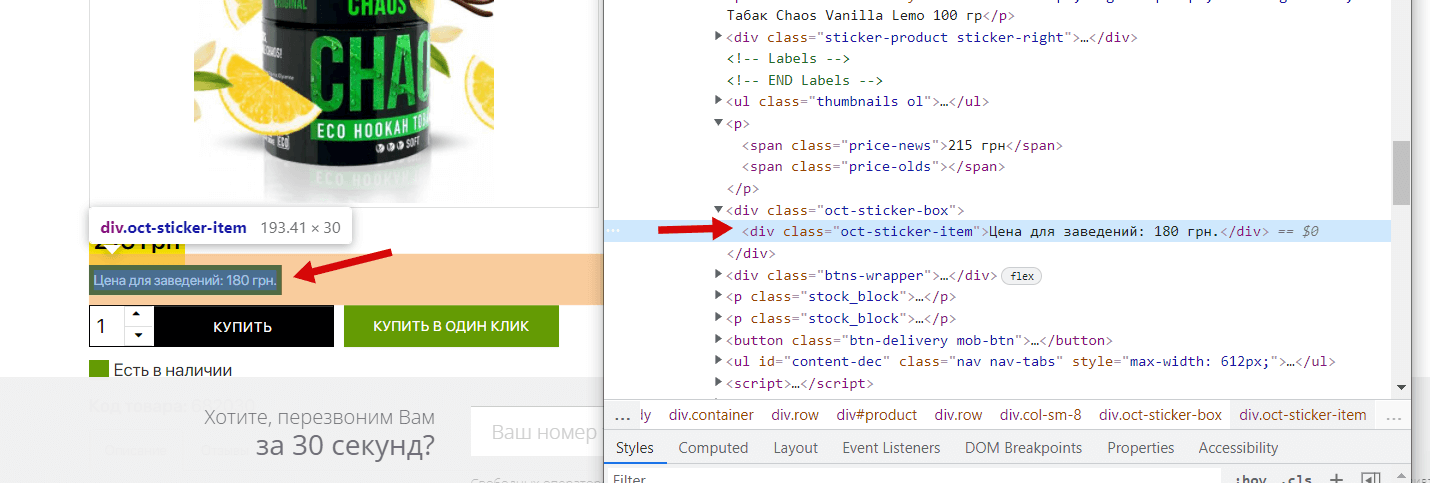
Итого мы имеем:
- Актуальная цена: Тег <span> с классом price-news
- Старая цена: Тег <span> с классом price-olds
- Цена для заведений: тег <div> с классом oct-sticker-item
Как сделать XPath и использовать его в парсерах?
-
- Способ первый: Вы можете прямо в коде скопировать XPath любого элемента:

Скопировав XPath, мы получаем следующий страшный код://*[@id=”product”]/div[1]/div[1]/p[2]/span[1]Этот вариант простейший, но не очень надежный, так как расположение одного и того же элемента в коде может отличаться из-за наличия или отсутствия других элементов в карточке товара и т.д. Поэтому нужно использовать второй способ.
- Способ второй: Суть этого варианта состоит в том, чтобы самому прописать нужный XPath без учета элементов, которые идут до необходимого нам блока. Это как из абсолютной ссылки сделать относительную.
Для того что бы сделать наш вариант XPath нужно использовать следующий элемент: // — это значит любое кол-во любых элементов Составив XPath по правилам, мы получаем готовые варианты для парсинга цен:
- Актуальная цена: //span[@class=”price-news”]
- Старая цена: //span[@class=”price-olds”]
- Цена для заведений: //div[@class=”oct-sticker-item”]
Куда вписывать XPath-запрос?
Для этого нам нужен один из спайдеров (парсеров). В данном случае это Screaming Frog Seo Spider. Заходим в Configuration -> Custom -> Extraction:

Дальше наши XPath нужно вписать в соответствующие строки и обязательно ставим справа опцию «Extract Text» если вам нужен только текст блока, а не весь его код:

Таким образом мы обращаемся к коду заданных страниц, спайдер в коде ищет нужный элемент, вне зависимости от его расположения и тащит из него текст. Результат будет таким:

Пример №2. Парсинг изображений
Задача – спарсить адреса изображений товаров. Рассмотрим на примере все того же сайта https://shishastore.com.ua/. И так, уже известным нам способом ищем в каком элементе расположена картинка товара:

Изображения состоят в элементе <a>, у которого class — thumbnail. Составляем XPath-запрос: //*[@id=”thumbnail-big”]/img/@src Здесь мы имеет тег <a> с классом thumbnail, далее идут различные внутренние элементы, которые мы исключаем звездочкой «*». После этого идет тег img из которого нам нужно вытащить ссылку, то есть содержимое тега src. Берем составленный XPath-запрос, в Screaming Frog переходим в Configuration > Custom > Extraction и парсим. Результат получаем следующий:

Теперь мы можем запустить парсинг по всему сайту и получить все УРЛ изображений товаров.

коммерческое предложение
Другие статьи автора

23/12/2022
Каннибализация ключевых слов - это явление, когда несколько страниц на сайте оптимизированы под одни и те же или похожие запросы и конкурируют между собой в выдаче, то есть удовлетворяют одному или похожему интенту. Поисковая система не может определить более релевантную из них, и ни одна из этих страниц не получает ТОП позиций, что снижает органическую эффективность сайта.

11/02/2025
Поисковые операторы Google являются полезным инструментом не только для SEO, но и для обычных пользователей. WEDEX расскажет обо всех особенностях работы с операторами поиска.

21/03/2025
Сегодня существуют два инструмента от Google, которые могут помочь в формировании семантики, поиска ключевых слов и просто изучения ниши. Называются эти средства «Похожие вопросы» и «Люди также ищут», и находятся прямо на главной странице поиска.
Последние статьи по #SEO

19/06/2025
Каждое обновление Google — это изменения в алгоритмах поиска, которые могут повлиять на видимость вашего сайта. Иногда это незначительные правки, иногда — масштабные Core Updates, которые перенастраивают принципы ранжирования.

18/06/2025
Картинки уже давно стали неотъемлемой составляющей SEO сайта и требуют особого внимания к себе не только со стороны SEO-специалистов, но и веб-разработчиков

17/06/2025
Поисковые роботы сканируют все имеющиеся в сети сайты для того, чтобы выяснить их соответствие конкретной тематике. Когда Google поймет, к какой категории относится веб-ресурс или конкретная страница, он начнет рекомендовать ее пользователям.