
 24/12/2021
24/12/2021  4432
4432

Інтернет-маркетинг
простою мовою
Зміст статті

XPath на допомогу SEO-фахівцеві: як правильно і швидко парсити конкурентів?
XPath — це така мова запитів до елементів XML або HTML документа. Робота XPath-запитів побудована декларативною мовою запитів, тобто, щоб отримати потрібні дані необхідно лише коректно поставити запит, що описує ці дані, а все інше зробить інтерпретатор мови XPath. Зручно? А як же, зручно і просто якщо розуміти цю мову. А які можливості має XPath для нас, тобто для SEO-фахівців? Давайте розумітися.
Основні можливості XPath
Які дані можна спарсувати?
- Будь-яку інформацію з коду практично з будь-якого сайту. Тут важливо розуміти, що ми можемо потрапити на сайт із захистом від парсингу. Наприклад, спарсити будь-який сайт Google не вдасться. Те саме стосується і Авіто, теж досить складно. Але більшість сайтів можна успішно спарсити.
- Ціни, наявність товарів та пропозицій, тексти, будь-які текстові характеристики, зображення та навіть 3D-фото.
- Опис, відгуки, структура сайту.
- Контактну інформацію (наприклад, пошту), неочевидні властивості тощо.
Всі елементи на сторінці, які є в коді сайту, можна успішно вивантажити в Excel.
Які обмеження при парсингу через XPath?
- Бан на user-agent. Деякі сайти забороняють доступ парсерам у яких в user-agent зазначено, що це програма. Це обмеження можна обійти, якщо в налаштуваннях виставити користувач-агент пошукової системи, наприклад. Для цього переходимо до Configuration> User-Agent та вибрати Googlebot.
- Заборона у robots.txt. Для обходу цієї заборони потрібно перейти в налаштування Screaming Frog у Configuration> Robots.txt> Settings та вибирати «Ігнорувати robots.txt»
- Бан IP. Тут є кілька варіантів вирішення проблеми: використовувати VPN або в налаштуваннях знизити швидкість парсингу сайту, щоб не викликати підозри та не потрапити під обмеження.
Як навчитися розуміти XPath і складати запити правильно?
Першим що необхідно зробити – це вивчити базовий синтаксис XPath, в мережі багато статей на цей випадок і достатня кількість прикладів парсингу різні елементів. Давайте розберемо кілька простих прикладів, які допоможуть зрозуміти основу мови XPath:
- //h1/text() – Заголовок Н1, саме текст
- //h1[@class=”header”]/text() – Заголовок Н1 з класом header, саме текст
- //span[@class=”new-price”] – Значення елемента span із класом new-price
- //input[@class=”addtocart”]/@title – Текст кнопки з класом addtocart, яка має назву в елементі @title
- //a/text() – Отримуємо текст посилання
- //a/@href – УРЛ посилання
- //img/@src – УРЛ зображення
- //div[4]/img/@src – Зображення в 4-му класі div по черговості
Розберемо складові запиту XPath на прикладі //div[@class=”default__button2 center”]/input/@value, цей запит має назву кнопки:
Як це відбувається:
- //div – ігноруємо всі елементи до потрібного нам, саме за це відповідає подвійний сліш «//». У цьому випадку ми вказали блок, у якому розташовано потрібну кнопку.
- [@class=”default__button2 center”] – у квадратних скобрах ми вказуємо особливість потрібного нам елемента, це може бути клас, ідентифікатор тощо.
- /input – далі вказуємо, власне, саму кнопку
- /@value – і вказуємо, що потрібно витягти з неї
Якщо ви використовуєте спайдер, наприклад Screaming Frog Seo Spider, то є налаштування що саме парсить: весь код або тільки текстове значення, якщо ж ви парсіте за допомогою Google таблиць, то нам потрібно вказати /text(), щоб спарсився тільки текст кнопки, без зайвого коду: //div[@class=”default__button2 center”]/input/@value/text() Тепер, коли ми розібралися з базовими атрибутами мови XPath, давайте на реальних прикладах використовуємо отримані знання та спарсим ціни та УРЛ зображень товарів.
Приклад №1. Парсинг ціни
Є чимало варіантів і програм за допомогою яких можна аналізувати цінову політику конкурентів, але половина з них працює незрозуміло як, друга половина платна і т.д. Ось тут на допомогу приходить парсинг цін конкурентів за допомогою XPath. Візьмемо для прикладу сайт https://shishastore.com.ua/ . Ми маємо ось таку типову картку товару, де є 2 варіанти цін – звичайна і для закладів.
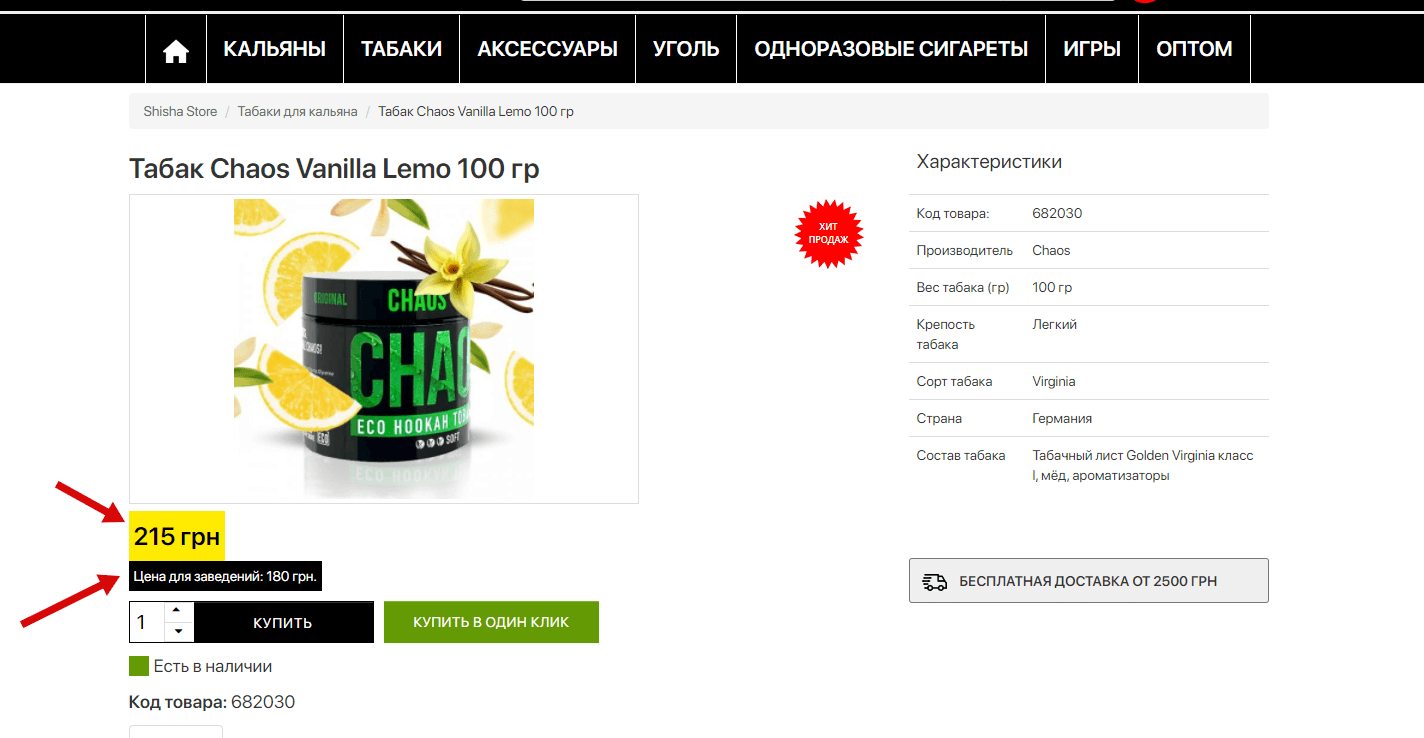
Для початку нам потрібно зрозуміти, в якому тезі/класі складається блок ціни в картці товару. Для цього потрібно подивитися код блоку, в Chrome це робиться при наведенні на потрібний елемент і натискання на праву кнопку миші, далі вибираємо «Подивитися код»:
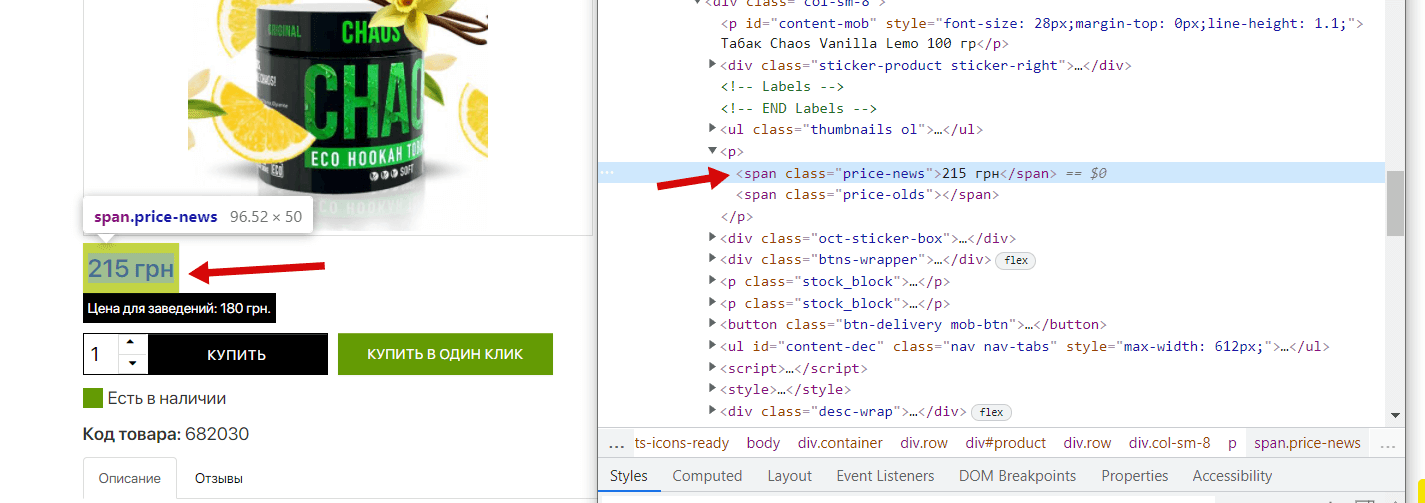
Бачимо, що ціна у нас полягає у тезі <span> з класом price-news, разом із цим помічаємо, що є ще й тег для старої ціни (у даному товарі її немає), його ми теж спаримо для повноти картини, що покаже нам на які товари та знижки робить конкурент. Тепер нам потрібно аналогічно дізнатись дані для блоку «Ціна для закладів», повторюємо дії:
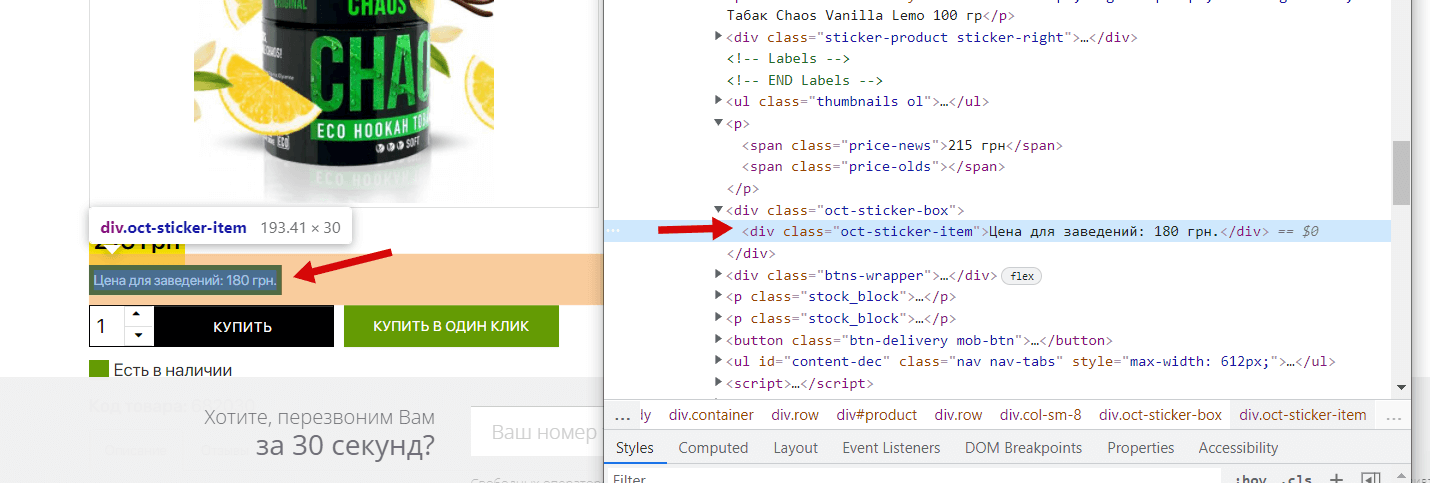
Отже ми маємо:
- Актуальна ціна: Тег <span> з класом price-news
- Стара ціна: Тег <span> із класом price-olds
- Ціна для закладів: тег <div> із класом oct-sticker-item
Як зробити XPath і використовувати його в парсерах?
-
- Спосіб перший: Ви можете прямо в коді скопіювати XPath будь-якого елемента:

Скопіювавши XPath, ми отримуємо наступний страшний код http://*[@id=”product”]/div[1]/div[1]/p[2]/span[1]Цей варіант найпростіший, але не дуже надійний, так як розташування одного і того ж елемента в коді може відрізнятися через наявність або відсутність інших елементів у картці товару тощо. Тому потрібно використати другий спосіб.
- Спосіб другий: Суть цього варіанта полягає в тому, щоб самому прописати потрібний XPath без урахування елементів, які йдуть до необхідного блоку. Це як із абсолютного посилання зробити відносну.
Для того щоб зробити наш варіант XPath потрібно використовувати наступний елемент: // – це означає будь-яку кількість будь-яких елементів Склавши XPath за правилами, ми отримуємо готові варіанти для парсингу цін:
- Актуальна ціна: //span[@class=”price-news”]
- Стара ціна: //span[@class=”price-olds”]
- Ціна закладів: //div[@class=”oct-sticker-item”]
Куди вписувати XPath-запит?
Для цього нам потрібен один із спайдерів (парсерів). У цьому випадку це Screaming Frog Seo Spider. Заходимо до Configuration -> Custom -> Extraction:

Далі наші XPath потрібно вписати у відповідні рядки та обов’язково ставимо праворуч опцію «Extract Text» якщо вам потрібен тільки текст блоку, а не весь його код:

Таким чином ми звертаємося до коду заданих сторінок, спайдер у коді шукає потрібний елемент, незалежно від його розташування та тягне з нього текст. Результат буде таким:

Приклад №2. Парсинг зображень
Завдання – спарсити адреси зображень товарів. Розглянемо на прикладі того ж сайту https://shishastore.com.ua/. І так вже відомим нам способом шукаємо в якому елементі розташована картинка товару:

Зображення складаються в елементі <a>, у якого class – thumbnail. Складаємо XPath-запит: //*[@id=”thumbnail-big”]/img/@src Тут ми маємо тег <a> з класом thumbnail, далі йдуть різні внутрішні елементи, які виключаємо зірочкою «*». Після цього йде тег img, з якого нам потрібно витягнути посилання, тобто вміст тега src. Беремо складений XPath-запит, в Screaming Frog переходимо до Configuration > Custom > Extraction і парсим. Результат отримуємо наступний:

Тепер ми можемо запустити парсинг по всьому сайту та отримати всі УРЛ зображень товарів.

комерційна пропозиція
Інші статті автора

29/07/2025
Додавання карти Google на сайт — це не просто модний елемент дизайну, а інструмент комунікації з клієнтом.

12/03/2025
Мета-теги це елементи коду html сторінки, які використовуються для надання додаткової інформації пошуковим системам про зміст сторінки.

16/07/2025
У жорсткій конкуренції за увагу користувачів важливо розуміти як визначити, наскільки ваш сайт заслуговує довіри пошукових систем.
Останні статті по #SEO

08/07/2026
Аналіз донора — це не перевірка однієї метрики, це зіставлення кількох метрик між собою.

29/06/2026
Якщо правильно працювати із запитами, можна краще розуміти свою аудиторію, точніше будувати структуру сайту, створювати релевантний контент і підсилювати SEO-результати без зайвих витрат.

19/06/2026
Крауд-маркетинг — це розміщення корисних, нативних згадок про бренд, продукт або послугу на майданчиках, де вже спілкується ваша аудиторія.