
 24/12/2021
24/12/2021  4021
4021


Інтернет-маркетинг
простою мовою
Content of the article

XPath to help an SEO specialist: how to parse competitors correctly and quickly?
XPath is such a query language for xml or html document elements. The work of XPath queries is built on a declarative query language, that is, to get the necessary data, you just need to correctly specify a query that describes this data, and the XPath language interpreter will do the rest. Conveniently? But how convenient and simple if you understand this language. And what opportunities does XPath have for us, that is, for SEO specialists? Let’s figure it out.
Key features of XPath
What data can be parsed?
- Any information from the code from almost any site. It is important to understand here that we can get to a site with protection from parsing. For example, you won’t be able to parse any Google site. The same applies to Avito, it is also quite difficult. But most sites can be successfully scraped.
- Prices, availability of goods and offers, texts, any text characteristics, images and even 3D photos.
- Description, reviews, site structure.
- Contact information (e.g. email), non-obvious properties, etc.
All elements on the page that are in the site code can be successfully uploaded to Excel.
What are the limitations when parsing via XPath?
- Ban by user-agent. Some sites deny access to parsers whose user-agent indicates that this is a program. This restriction can be bypassed by setting the user agent of the search engine in the settings, for example. To do this, go to Configuration> User-Agent and select Googlebot.
- Prohibited in robots.txt. To bypass this ban, you need to go to the Screaming Frog settings in Configuration> Robots.txt> Settings and select “Ignore robots.txt”
- Ban by IP. There are several options for solving the problem: use a VPN or reduce the site parsing speed in the settings so as not to arouse suspicion and not fall under restrictions.
How can I learn to understand XPath and write queries correctly?
The first thing to do is to learn the basic syntax of XPath, there are many articles on the net for this case and a sufficient number of examples of parsing various elements. Let’s look at a few simple examples to help you understand the basics of the XPath language:
-
- //h1/text() – Heading H1, text
- //h1[@class=”header”]/text() – H1 heading with header class, text
- //span[@class=”new-price”] – The value of the span element with the class new-price
- //input[@class=”addtocart”]/@title – The text of a button with the addtocart class, whose title is in the @title
element
- //a/text() – Get link text
- //a/@href – URL of the link
- //img/@src – Image URL
- //div[4]/img/@src – Image in 4th class div
Let’s analyze the compound XPath queries using the example //div[@class=”default__button2 center”]/input/@value, this query parses the name of the button:
How does it happen:
- //div – we ignore all the elements up to the one we need, this is what the double slash “//” is responsible for. In this case, we have specified the block in which the desired button is located.
- [@class=”default__button2 center”] – in square brackets we indicate the distinctive feature of the element we need, it can be a class, identifier, etc.
- /input – then we indicate, in fact, the button itself
- /@value – and specify what needs to be pulled out of it
If you use a spider, for example Screaming Frog Seo Spider, then there is a setting what exactly to parse: the entire code or only the text value, but if you parse using Google Sheets, then we need to specify /text() so that only the button text is parsed, without extra code: //div[@class=”default__button2 center”]/input/@value/text() Now that we have dealt with the basic attributes of the XPath language, let’s use the acquired knowledge on real examples and parse prices and URLs of product images.
Example #1. Price parsing
There are many options and programs with which you can analyze the pricing policy of competitors, but half of them work incomprehensibly, the second half are paid, etc. This is where parsing competitor prices with XPath comes in. Let’s take the site https://shishastore.com.ua/ as an example. We have such a typical product card, where there are 2 price options – regular and for establishments.
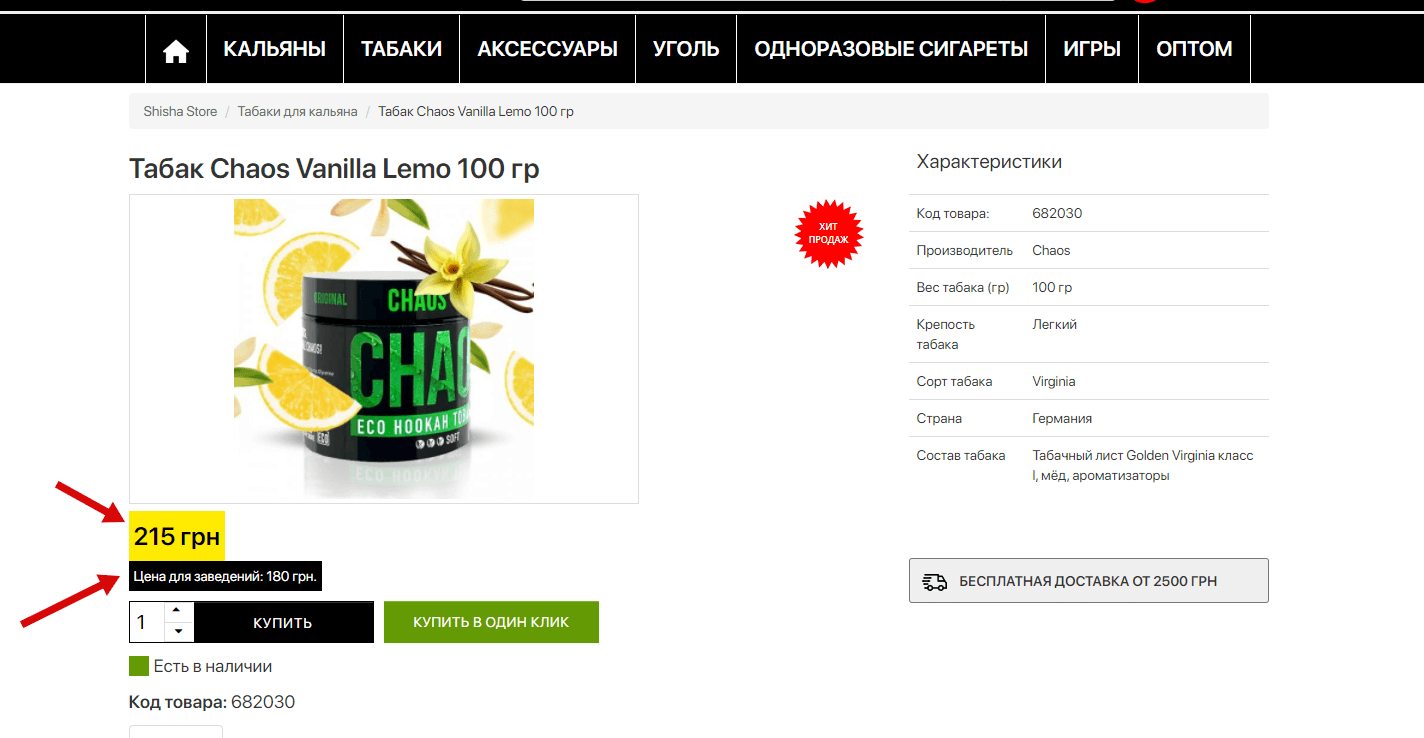
First, we need to understand what tag/class the price block in the product card consists of. To do this, you need to look at the code of the block, in Chrome this is done by hovering over the desired element and by pressing the right mouse button, then select “View Code”:
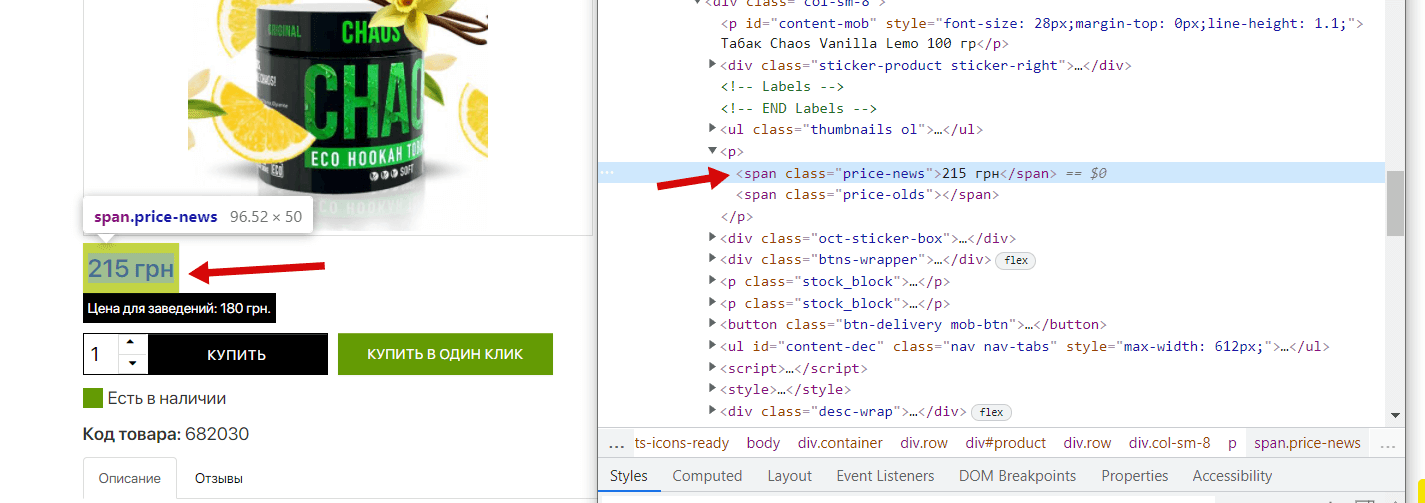
We see that our price is in the <span> with the price-news class, along with this, we notice that there is also a tag for the old price (it is not in this product), we will also parse it for completeness, which will show us what products and what discounts the competitor makes. Now we need to similarly find out the data for the “Price for establishments” block, repeat the steps:
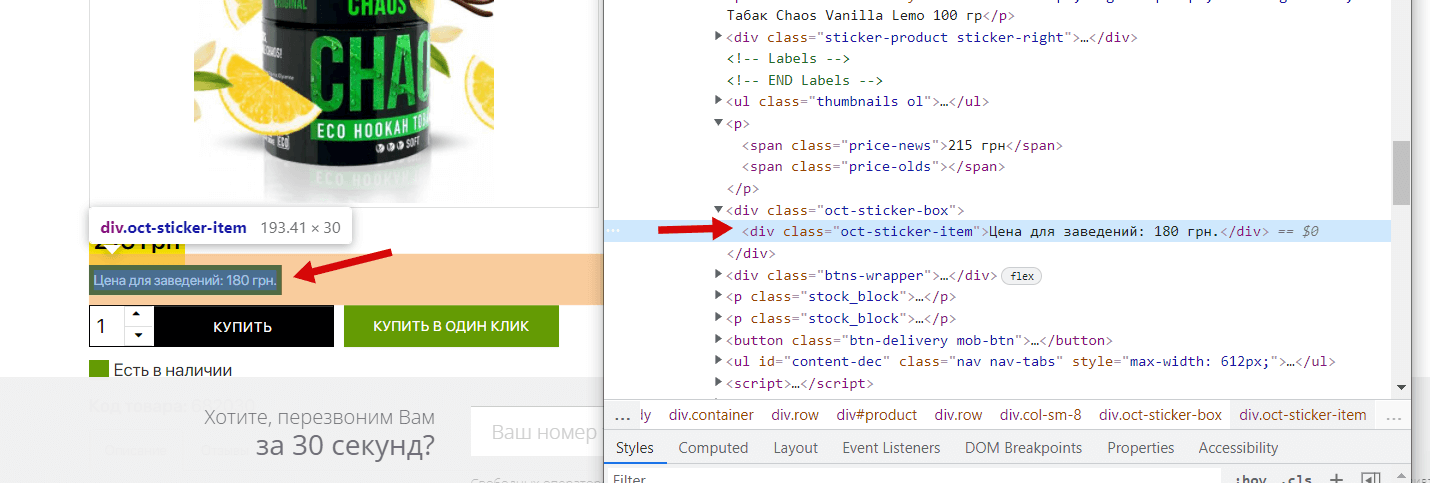
In total we have:
- Actual price: Tag <span> with class price-news
- Old Price: Tag <span> with class price-olds
- Institution price: <div> with class oct-sticker-item
How to make XPath and use it in parsers?
-
- Method one: You can copy the XPath of any element directly in the code:

By copying the XPath, we get the following terrible code: //*[@id=”product”]/div[1]/div[1]/p[2]/span[1]This option is the simplest, but not very reliable, because how the location of the same element in the code may differ due to the presence or absence of other elements in the product card, etc. Therefore, you need to use the second method.
- Method two: The essence of this option is to prescribe the required XPath yourself without taking into account the elements that go before the block we need. It’s like turning an absolute link into a relative one.
In order to make our version of XPath, you need to use the following element: // – this means any number of any elements Compiling XPath according to the rules, we get ready-made options for parsing prices:
- Actual price: //span[@class=”price-news”]
- Old price: //span[@class=”price-olds”]
- Price for establishments: //div[@class=”oct-sticker-item”]
Where should I put the XPath query?
For this we need one of the spiders (parsers). In this case it is Screaming Frog Seo Spider. Go to Configuration -> Custom -> extraction:

Next, our XPath needs to be entered in the appropriate lines and be sure to set the “Extract Text” option on the right if you need only the text of the block, and not all of its code:

Thus, we turn to the code of the given pages, the spider in the code looks for the desired element, regardless of its location, and drags text from it. The result will be like this:

Example #2. Parsing images
The task is to parse the addresses of product images. Consider the example of the same site https://shishastore.com.ua/. And so, in a way already known to us, we are looking for in which element the product image is located:

Images are contained within an <a> element whose class is thumbnail. Compose an XPath query: //*[@id=”thumbnail-big”]/img/@src Here we have the <a> with the thumbnail class, followed by various internal elements, which we exclude with an asterisk “*”. After that comes the img tag from which we need to pull out the link, that is, the contents of the src tag. We take the compiled XPath query, in Screaming Frog go to Configuration > custom > Extraction and parsing. We get the following result:

Now we can parse the entire site and get all the product image URLs.

commercial offer
Other articles by the author

14/04/2023
A technical SEO audit is a process that checks the various technical parts of a website to make sure they are in line with search engine optimization best practices. This means the technical parts of your website that are directly related to the ranking factors of search engines like Google or Bing.

05/03/2025
The URL address provides access to a website. In simple terms, an email address is a record of where a website is located, and the browser uses this address to provide the user with access to the website or certain materials from the server.

25/09/2025
In the business environment, this indicator is often considered a sign of stability: the older the domain, the more likely it is that the project is active, authoritative, and developing.
Latest articles by #SEO

06/05/2026
DNS, or the domain name system, is a hierarchical system that helps a browser find the correct IP address for a domain.

27/04/2026
Googlebot is Google Search's primary web crawler. It collects information about web pages so that Google can index them and use them in search results.

21/01/2026
For businesses, slow server response times mean a higher risk of user drop-offs, lost sales, and reduced marketing ROI.