
 07/02/2024
07/02/2024  4036
4036


Інтернет-маркетинг
простою мовою
Содержание статьи
Как подобрать ключевые слова в Serpstat?
Serpstat – это многофункциональная SEO онлайн-платформа, которая заменяет множество разнообразных сервисов и содержит 5 модулей.
- Поисковая аналитика. Этот модуль позволяет проанализировать конкурентов, собрать семантику и найти ключевые фразы.
- Анализ внешних ссылок. Здесь можно получить данные о ссылочных донорах, анкорах, а также проконтролировать изменения в ссылочном профиле (как своего домена, так и конкурентов).
- Мониторинг позиций. С помощью этого модуля есть возможность проверить позиции в органической выдаче своего домена и конкурентов. А еще подкорректировать стратегию продвижения, благодаря анализу конкурентов и доли трафика по определенным категориям.
- Аудит сайта. Можно найти ошибки, которые оказывают влияние на позиции сайта. Тут же будут рекомендации по устранению этих ошибок.
- Кластеризация и текстовая аналитика. Вы сможете сгруппировать большой объем ключей для того, чтобы создать правильную структуру сайта. Также получите рекомендации по написанию контента, который сможет выйти в топ поисковой выдачи.
Преимущества и недостатки сервиса
Это незаменимый инструмент, который отлично подойдет как для крупных компаний по SEO-продвижению, так и для отдельных SЕО-специалистов. У сервиса хорошее соотношение цены и качества, а также есть свои плюсы и минусы. Рассмотрим их детальнее.
Преимущества
- Есть пробный период и русский язык, что многим облегчает использование;
- Развернутая аналитика семантики в нише;
- Можно определить проблемные места проекта и получить рекомендации по их исправлению;
- Есть возможность провести анализ рекламных объявлений конкурентов и подготовить свои, учитывая ошибки других;
- Хорошая база ключевых слов, быстрые отчеты и выгрузки;
- Также вы сможете отследить изменения в выдаче, после чего доработать страницы с просевшими позициями.
Недостатки
- Использование сервиса нужно оплачивать. Цены не высокие, но чем больше функций вам нужно, тем выше оплата;
- Иногда долгое обновление данных;
- Нет возможности установить или поменять временные интервалы при получении данных, что для аналитики может играть решающую роль.
Как использовать сервис для подбора ключевых слов
Как же начать поиск ключевых слов после того, как мы вошли в аккаунт?
Смоделируем ситуацию: вы планируете запустить свой собственный интернет-магазин, например, по продаже детской одежды. И, соответственно, необходимо собрать семантику, чтобы сформировать хорошую структуру и оптимизировать поисковые запросы на страницах вашего сайта.
Первое, что нам нужно – это подобрать маркерный запрос, лучше всего описывающий тематику вашего сайта. В нашем случае для того, чтобы собрать всю имеющуюся семантику для магазина детской одежды, лучший общий маркер – это «детская одежда».
Но перед тем, как непосредственно перейти к инструменту подбора ключевых слов, рекомендуем сначала проверить ваш маркерный запрос по показателям для того, чтобы убедиться, действительно ли он нам подходит и охватывает ли все возможные варианты ключей. Для этого нам понадобится следующая вкладка.
Суммарный отчет
Слева на панели инструментов выбираем вкладку «Анализ ключевых слов» – «Суммарный отчет».
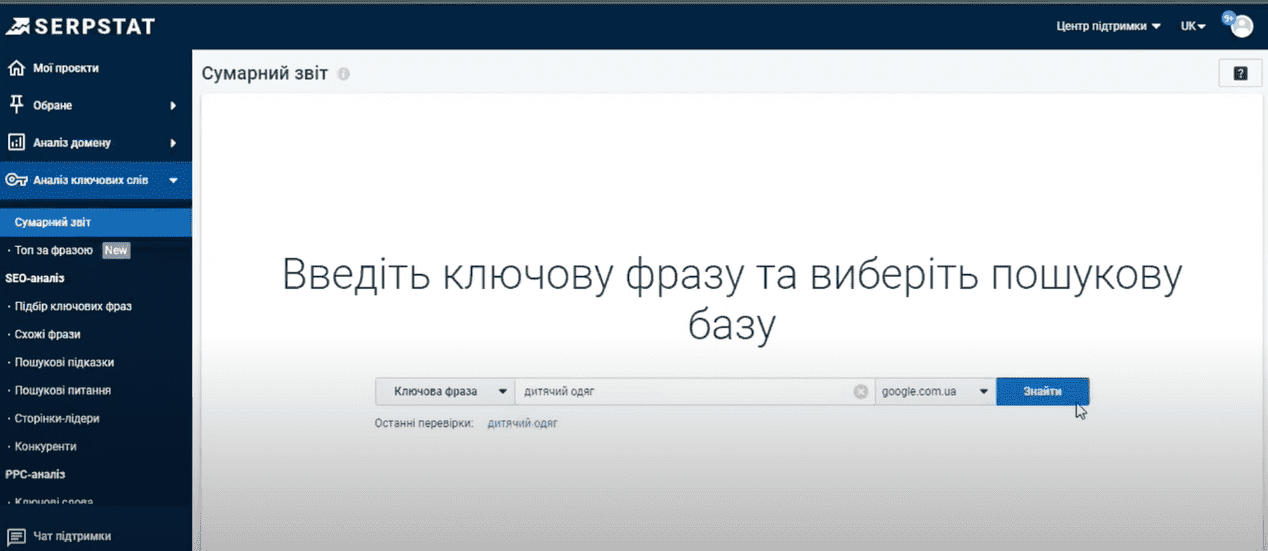
Вводим наш маркерный запрос «Детская одежда» и нажимаем кнопку «Найти». Сразу обращаем ваше внимание, что необходимо проверить правильно выбранный регион поиска. Нас интересуют запросы по Украине, проверяем.
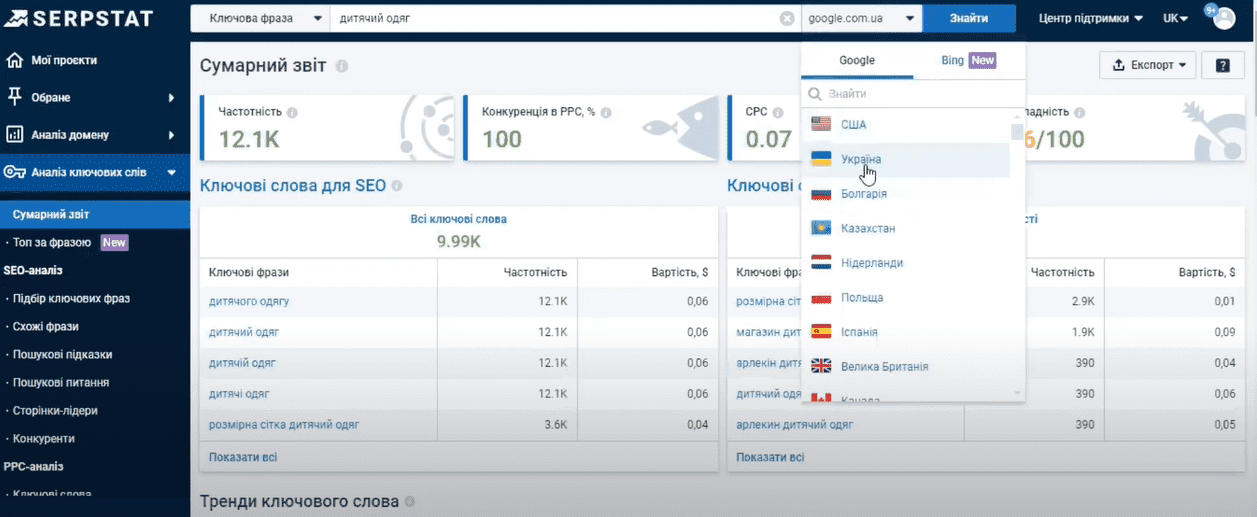
На странице суммарного отчета представлена общая информация о маркере или поисковом запросе, который мы анализируем.
Первое, что мы видим, это 4 основные метрики:
- Частотность – средний показатель количества запросов в месяц.
- Показатель конкуренции в контекстной рекламе
- Средняя цена за клик в контексте. Она указана в долларах США. Но как показывает практика, это очень обобщенная средняя стоимость, почти не имеющая ничего общего с реальной стоимостью.
- Сложность ключевого слова. Этот показатель дает понимание, насколько тяжело этот ключ поднять в ТОП Google с помощью SEO-продвижения.
Далее на странице мы видим две таблички с вариантами ключевых слов для СЕО и контекста. Базовую информацию об их количестве, частотности и стоимости за клик. Ниже представлен график тренда для нашего маркерного запроса.
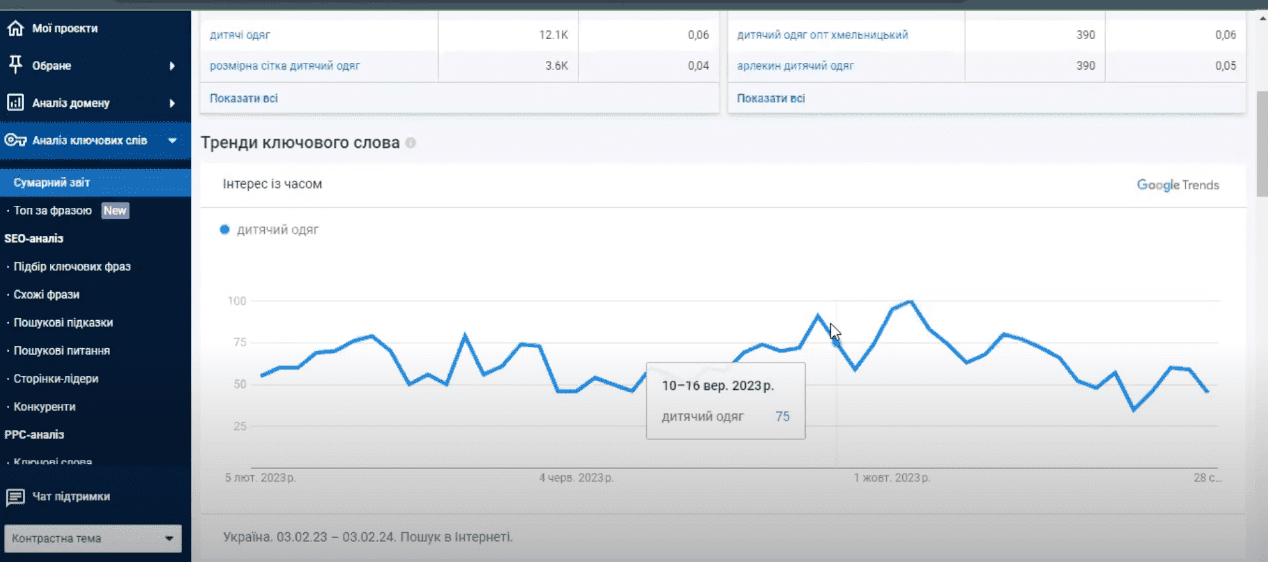
Эти данные сервис берет непосредственно из сервиса Google Trends. Диапазон по умолчанию у нас – год. Если нам нужен более широкий диапазон, то можно воспользоваться сервисом Google Trends или инструментом прогнозирования в Google Ads. Это действительно полезная информация, которая дает нам возможность понять реальный спрос ключевого слова (есть ли сезонная зависимость или какова его динамика). Потому что есть ситуации, когда мы видим, что популярность определенного поискового запроса стала уменьшаться со временем. И это свидетельствует о том, что его использование не принесет в будущем желаемого для нас показателя органического трафика.
Ниже расположена общая табличка и график с доменами, ранжируемыми по нашему маркерному запросу и их основные показатели. Такую же табличку мы видим и для доменов, использующих нашу фразу или ее вариацию в контекстной рекламе. И по отдельности примеры объявлений с нашим маркерным запросом.
Теперь переходим непосредственно к поиску ключевых слов.
Подбор ключевых фраз
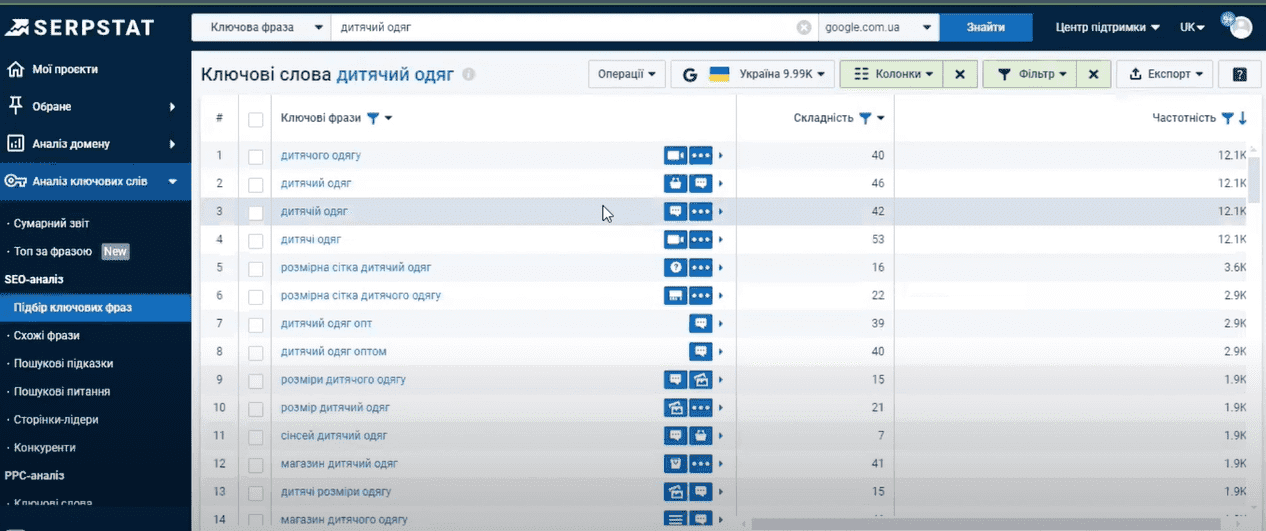
Мы видим все варианты ключей нашего маркерного запроса.
Сразу обращаем ваше внимание на одно отличие от планировщика ключевых слов в Google Ads – мы не можем вводить сразу несколько маркерных запросов для того, чтобы сделать подбор более точным или использовать несколько синонимов ключевой фразы. Таким образом, для комплексного сбора ключей необходимо вводить разные варианты наших маркерных запросов и анализировать полученные результаты по отдельности. А это не совсем комфортно. Но в отличие от того же Google Planner, Serpstat показывает те варианты ключевых слов, которые Google Ads не отображает, потому что они относятся к серым темам.
И второе преимущество – Serpstat отображает ультранизкочастотные запросы. На самом деле, это запросы, что пользователи крайне редко гуглят, но это может быть полезно при работе со сложными нишами. У каждого варианта ключевого слова мы видим информацию в виде небольших иконок о том, где сервис нашел этот запрос, и колонки с разными показателями по каждому ключевому запросу.
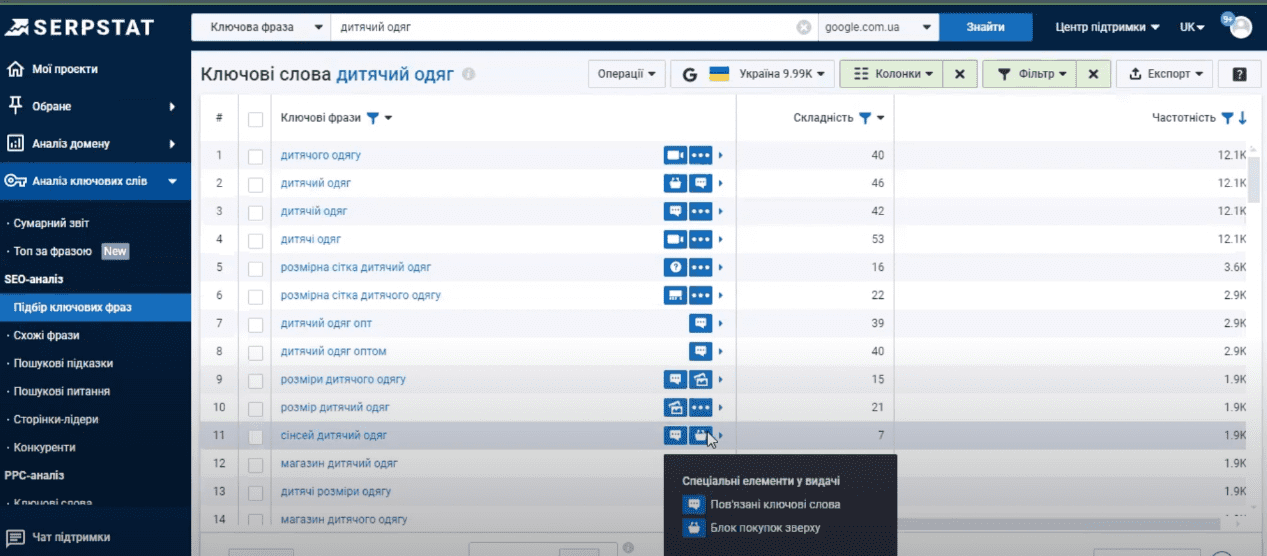
По желанию отдельные колонки можно убрать или добавить. Для этого есть подходящий функционал (кнопка «Колонки»), где можно отметить необходимые нам чек-боксы. У каждой колонки по показателю имеется собственный фильтр. То есть, мы можем сортировать таблицу по отдельному параметру. К примеру, нужно видеть в первую очередь запросы с частотностью в диапазоне от 100 до 1000.
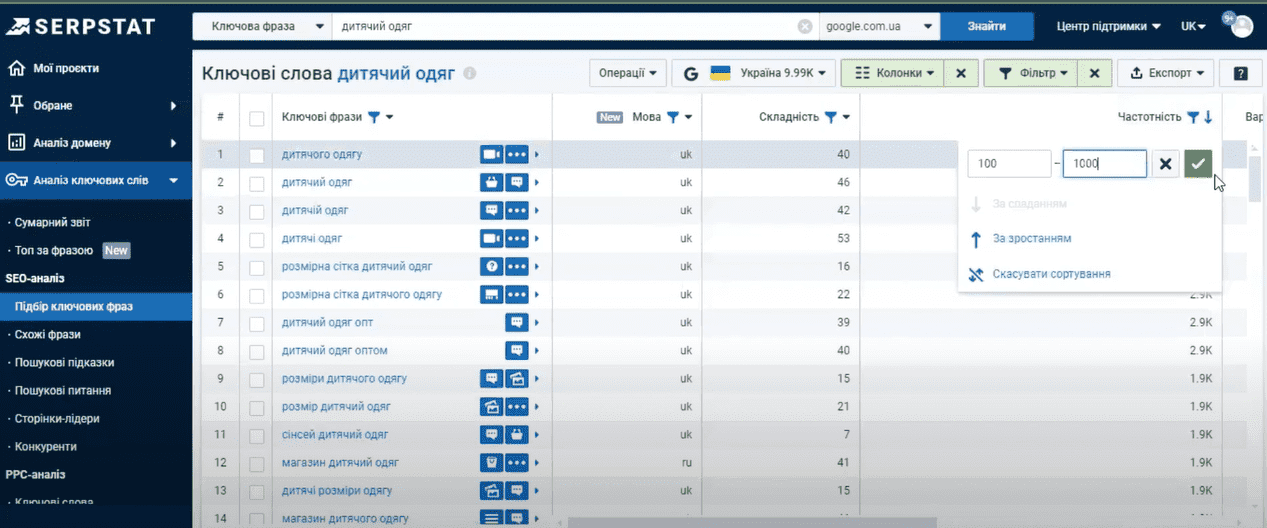
Для того, чтобы вручную не перебирать десятки тысяч вариантов ключей, есть отдельный фильтр, с помощью которого мы можем настроить необходимые для нас параметры.
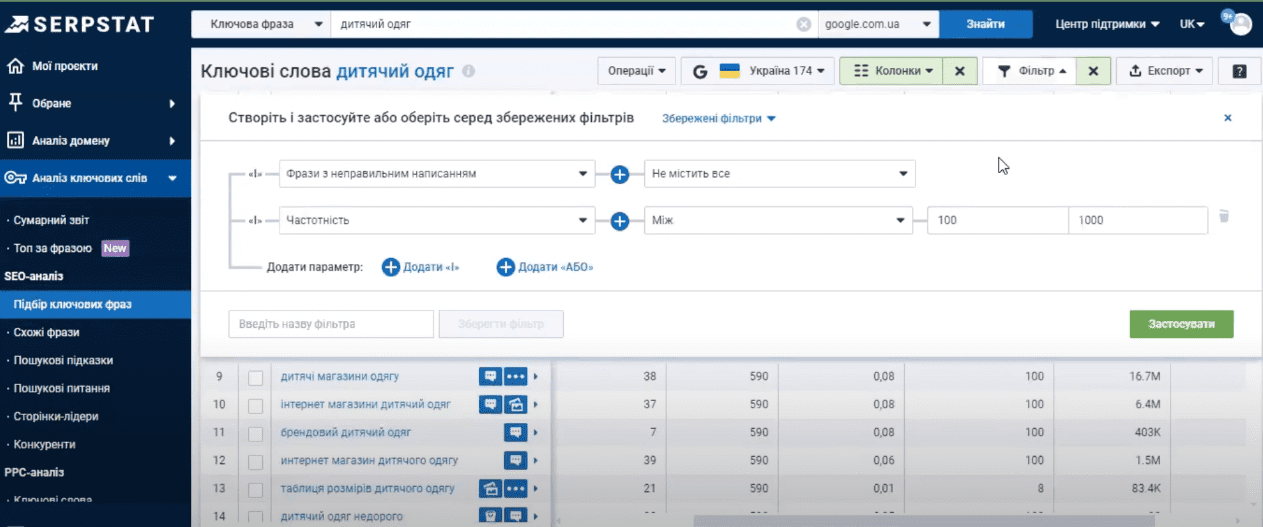
По умолчанию в таблице не отображаются слова с неправильным написанием.
Далее мы хотим исключить из списка запросы, которые нам 100% не подходят. Это можно сделать с помощью параметра «Ключевые фразы». Выбираем «Не содержит все» (широкое соответствие) и вводим минус-слова (через запятую), которых не должно быть в нашей семантике. К примеру, «дешево».
Если выбрать широкое соответствие, сервис автоматически удалит все словоформы указанных минус-слов. К примеру, «дешево»/«дешевый». А если указать точное соответствие, то соответственно останутся только те слова, которые точно соответствуют заданным условиям.
Можно добавить фильтр, чтобы убрать все топонимы. То есть запросы, содержащие название города. К примеру, если вы планируете продажу продукции по всей Украине, то запросы типа «детская одежда Хмельницкий» вам не нужны. Чтобы их убрать, выбираем параметр “Фильтрация по топонимам” – “Не содержит все”.
Ну и мы не хотим использовать поисковые запросы со сверхнизкой частотой и нам необходимо их убрать. Для этого добавляем параметр «Частотность» – «Больше чем» – «500». Жмем «Применить».
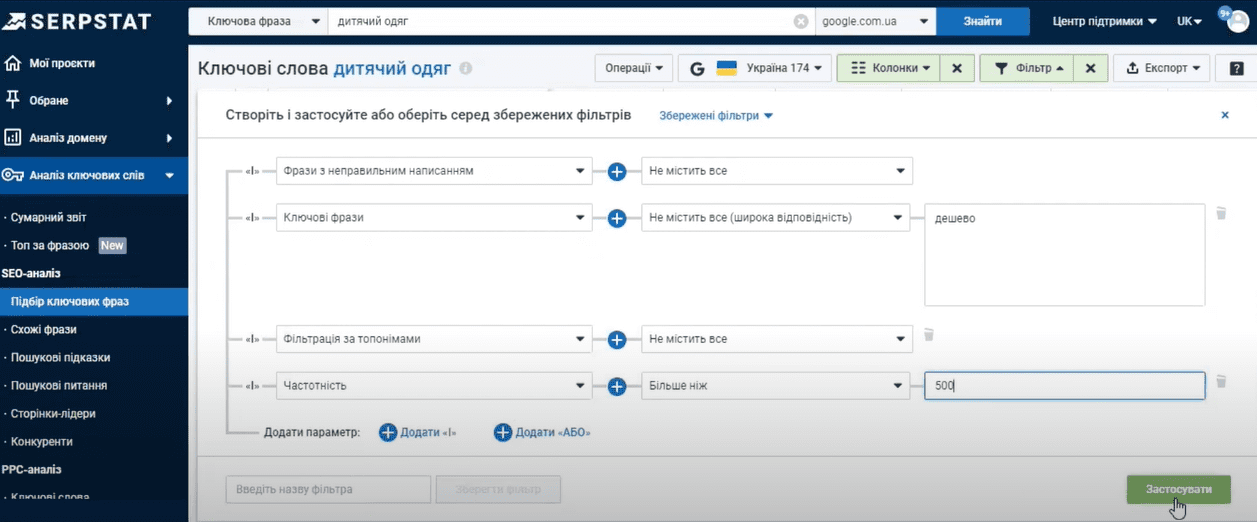
И вместо 10 000 вариантов у нас осталось менее 300.
Параметров фильтра и их значений достаточно много. Рекомендуем вам ознакомиться с ними. Это поможет вам экономить время при работе с поиском семантики.
Мы сформировали наш список с вариантами ключевых слов. Можно его выгрузить отдельным файлом и использовать для своих нужд. Для этого выбираем необходимый формат и кликаем на кнопку «Экспорт». Для функционала экспорта был разработан очень удобный дополнительный функционал, с помощью которого можно указать, какие колонки таблицы следует экспортировать. Есть возможность убрать лишнее или наоборот – добавить необходимые данные в таблицу.
После нажатия кнопки экспорта через 5-10 секунд появится уведомление, что документ готов к загрузке. Или можно перейти на страницу «Последние отчеты» через иконку профиля и загрузить файл.
Кроме экспорта файла имеется отдельный функционал взаимодействия с запросами через кнопку «Операции». К примеру, выбираем чек-боксами ключи, которые нам нужны. Нажимаем на кнопку «Операции» и выбираем интересующее нас действие:
- Скопировать ключи в буфере обмена. Целую таблицу, строку или фразу.
- Добавить запросы в проект мониторинга, если у вас создан проект.
- Добавить фразы к пакетному анализу. Это инструмент, который позволяет собирать и хранить списки ключевых фраз. Также эти списки можно редактировать по необходимости.
- Добавить фразы к кластеризации (о ней мы поговорим чуть позже).
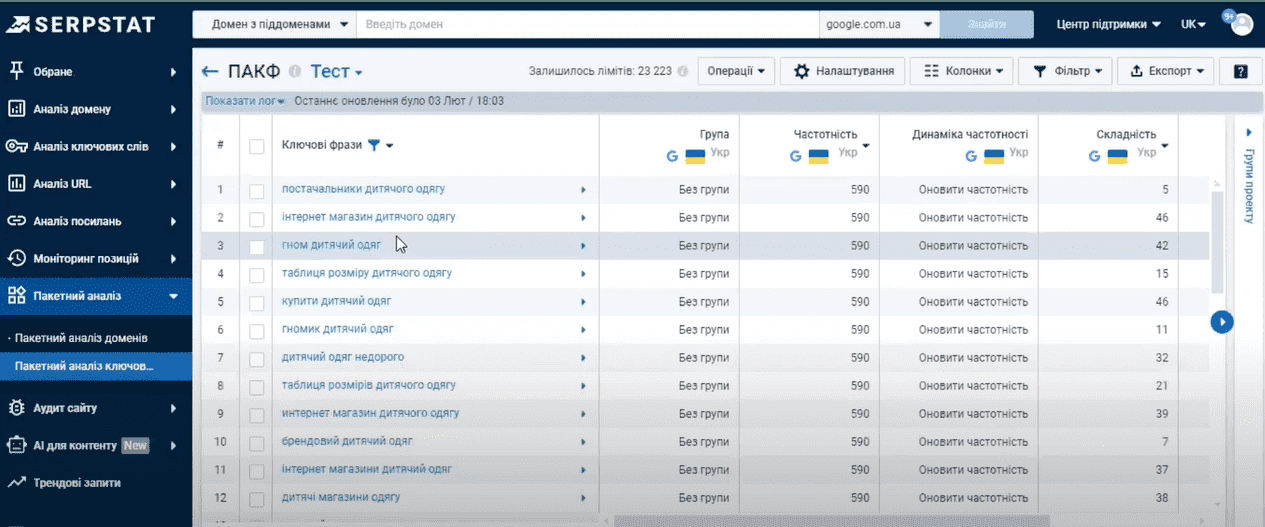
Для удобства, будем добавлять наши найденные ключи в пакетный анализ, чтобы не работать с отдельными файлами. Для этого кликаем на соответствующее значение. Жмем «Создать проект». Вносим имя, выбираем поисковик, выбираем параметры, которые должны отображаться в проекте для ключей.

И дополнительно, по лимитам, мы можем выполнить автоматический сбор дополнительной семантики в автоматическом режиме. Но сейчас мы это сделаем вручную. Нажимаем «Создать проект» и переходим в инструмент пакетного анализа, где сохранены наши ключи.
Мы провели подбор ключевых слов по маркерному запросу, но часто бывает, что при поиске мы не учитываем другие синонимы фразы, какие-то неожиданные вариации, которыми пользователи пользуются в поиске. Например, кто-то пишет «детская одежда», кто-то – «одежда для детей» или «одежда для ребенка», а кто-то напишет «одежда для малышей или малышни». И все это – разные запросы, с разной частотностью и уровнем сложности продвижения в поиске.
Похожие фразы
Вводим наш маркерный запрос, нажимаем кнопку «Найти» и анализируем дополнительные варианты ключевых слов.
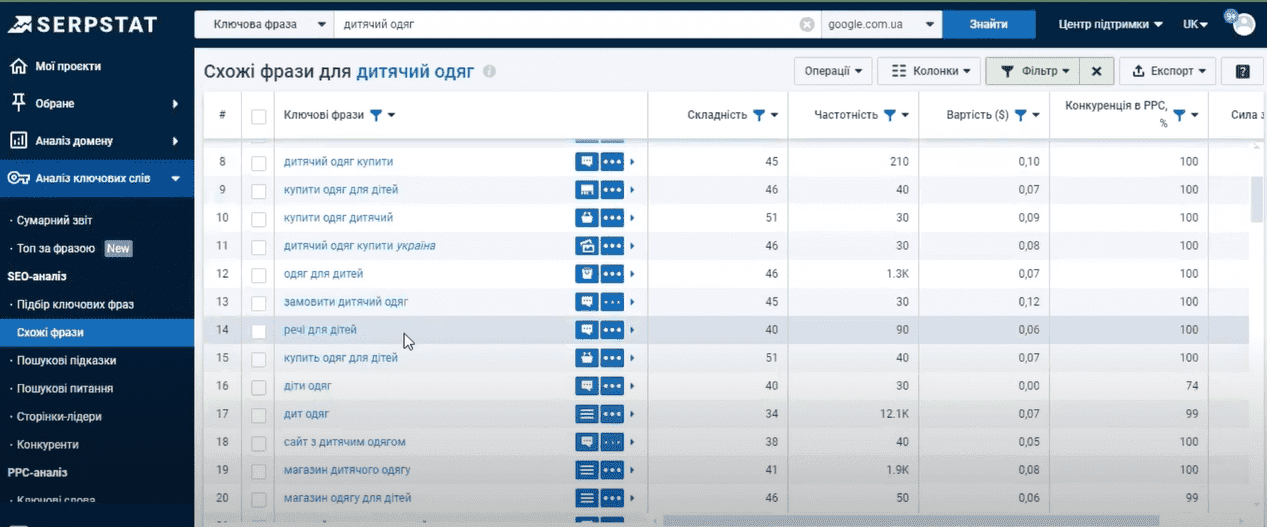
Мы видим новые варианты ключевых фраз, которые можно использовать для оптимизации на нашем сайте. Функционал этого инструмента абсолютно идентичен инструменту подбора ключевых слов.
Отфильтруем ключи по частотности от 500 и добавим новые фразы к нашему проекту пакетного анализа. Если среди новых фраз есть уже существующие в проекте пакетного анализа, то они будут автоматически удалены.
На этом базовый выбор поисковых фраз можно завершить. Но, если вам нужно качественно проработать семантику и собрать наиболее полное семантическое ядро, то дальше мы переходим к следующему инструменту.
Поисковые подсказки
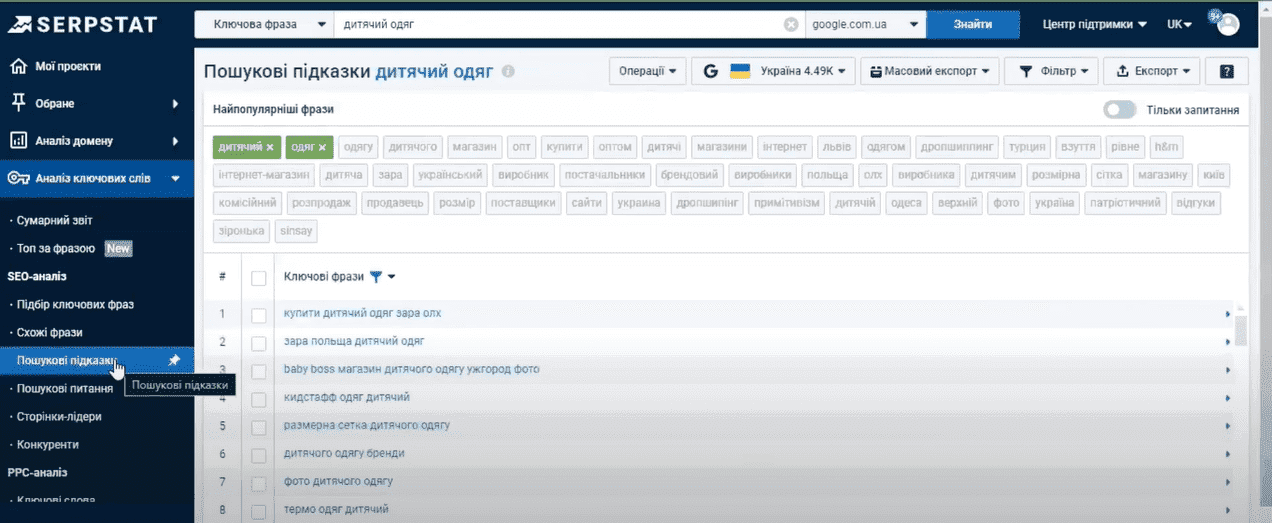
Особенность этого инструмента заключается в том, что он генерируется в реальном времени и отображает запросы и вопросы людей, которые ищут ответы и информацию сейчас. То есть, это появляющиеся варианты подсказок, которые отображаются, когда вы начинаете вводить запрос в поисковую строку. По нашему маркеру мы находим более 4000 вариантов.
Фильтр в этом отчете не работает таким же образом, как и в предыдущих отчетах, но подбор запросов можно конкретизировать посредством добавления слов в фразу. К примеру, добавляем к нашему маркеру слова «Магазин» и «Интернет». Нажимаем на эти слова прямо в списке сверху. После этого у нас остается всего 190 фраз, которые мы также можем добавить в наш проект пакетного анализа.
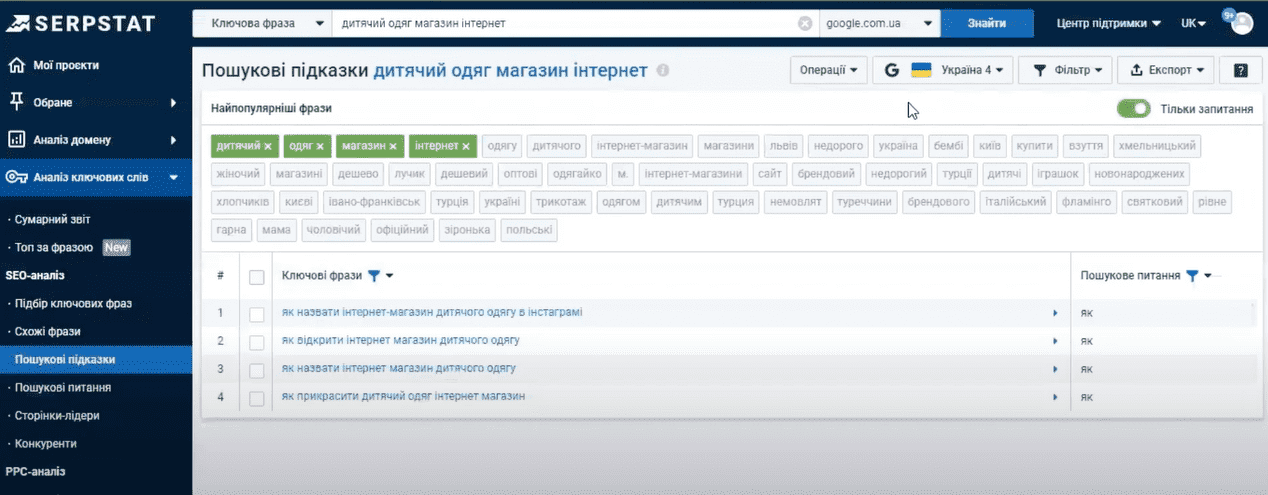
Поисковые вопросы
У этого инструмента есть еще один полезный функционал – это кнопка «Только вопрос».
С ее помощью можно фильтровать фразы только посредством вопросов. И следует отметить, что на панели инструментов для этого есть отдельная вкладка, которая как раз и выполняет этот функционал, а именно – анализ запросов в виде вопроса. Здесь мы видим все варианты возможных вопросов, содержащих нашу маркерную фразу. Эти фразы можно использовать для подбора тем для блога, формирования контент-плана или формирования блока FAQ на сайте.
Функционал отчета не отличается от отчета по поиску подсказок. Давайте возьмем все эти варианты вопросов и добавим в наш проект пакетного анализа. Для этого по-прежнему ставим галочку возле «Ключевые фразы», далее – «Операции», «Добавить фразы в Пакетный анализ фраз».
Кроме поиска ключей с помощью маркерного запроса можно выполнить конкурентный анализ. Рассмотрим детальнее.
Страницы-лидеры
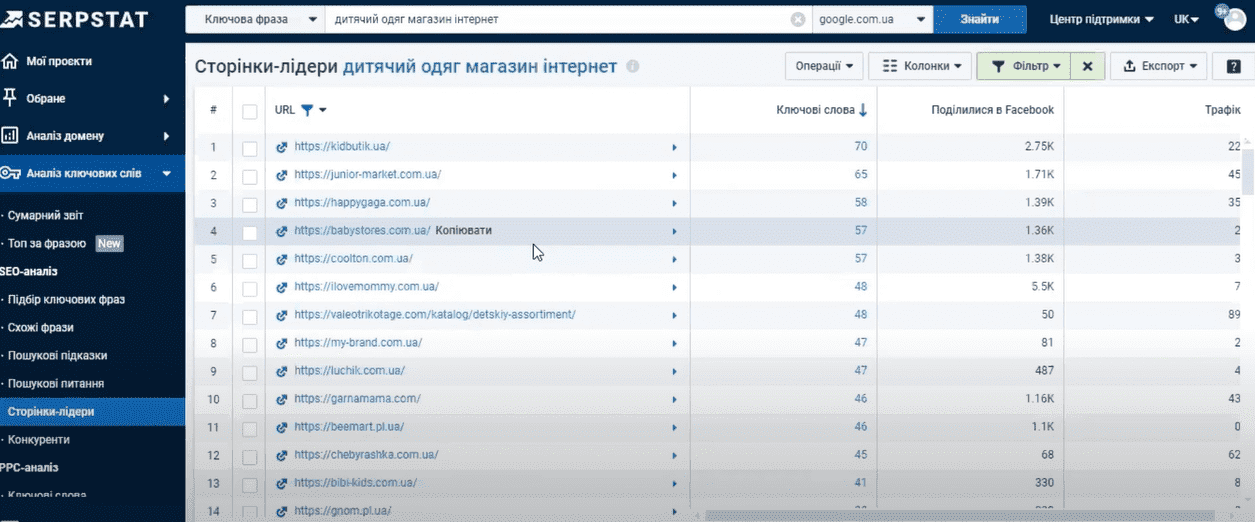
В этом отчете мы видим список страниц, которые ранжируются по нашему маркерному запросу и получают наибольшее количество трафика. Если поверхностно осмотреть список и переходить на эти страницы с помощью соответствующих кнопок, мы можем в целом понять, какие из этих страниц релевантны для нашего будущего сайта. Выбираем конкурента и кликаем на ссылку.
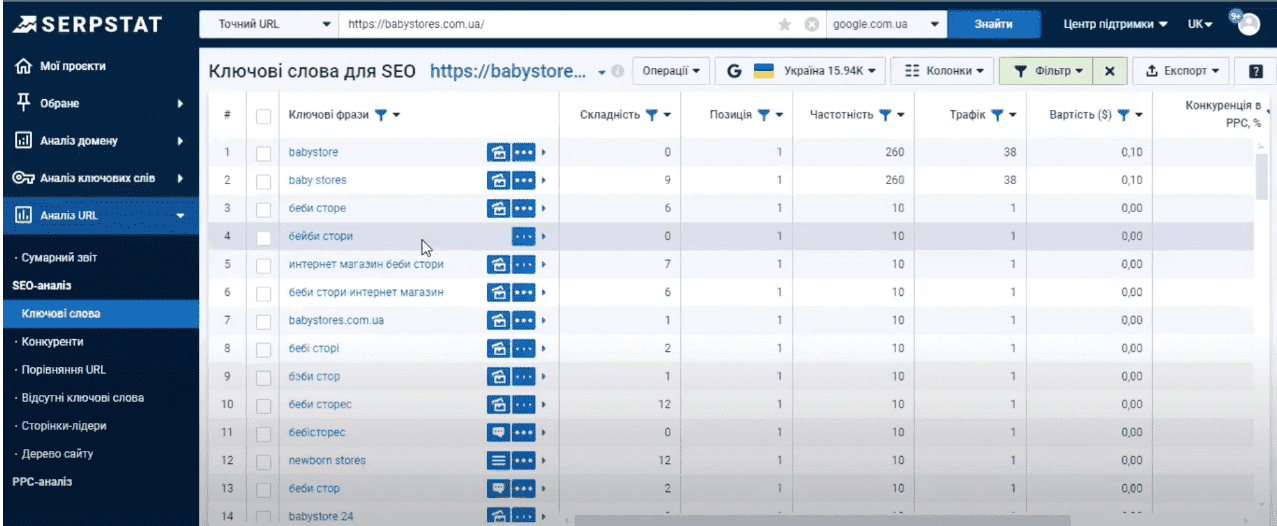
Открывается суммарный отчет по нашему URL. В нем мы видим полный список запросов, их сложность, частотность и позицию, занимаемую по нему текущей страницей. То есть, мы получаем понимание, по каким именно запросам оптимизирована страница конкурента и, как мы можем этот опыт интерпретировать на собственном ресурсе.
Мы также можем фильтровать отчет, полностью экспортировать его или выбрать интересующие нас ключи и добавить в проект пакетного мониторинга.
Конкуренты
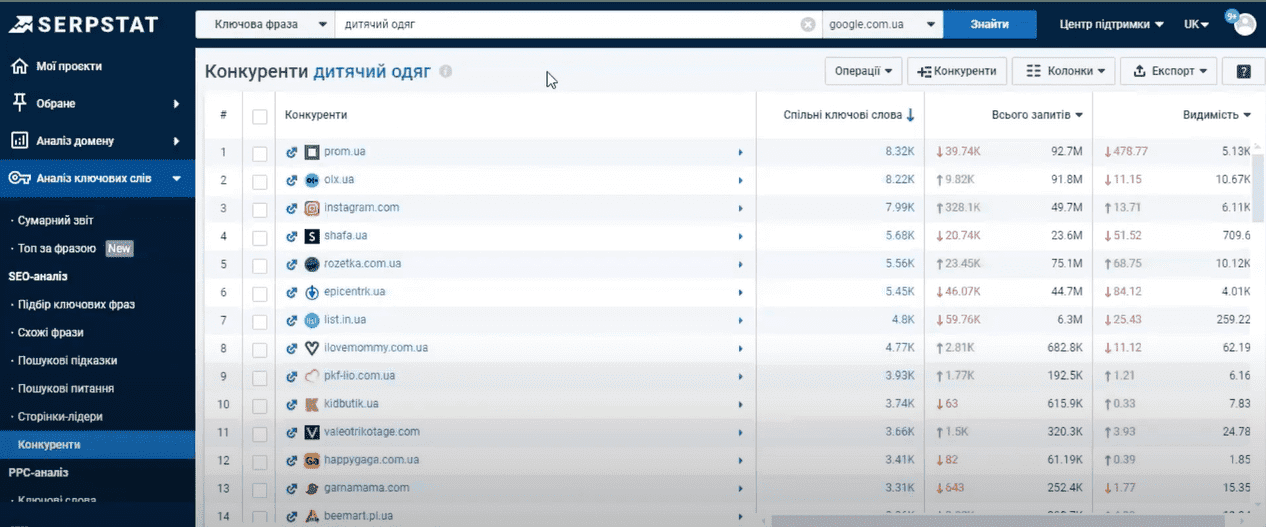
Этот инструмент не так интересен нам в плане семантики, а больше служит для того, чтобы сформировать список потенциальных конкурентов по нашей маркерной фразе. Видим список доменов, ранжируемых по нашему поисковому запросу. Отчет также формируется в реальном времени, поэтому иногда для его формирования необходимо определенное время.
В отчете мы видим список доменов и колонки с общей информацией. Наиболее интересное для нас – это «Общие ключевые слова», то есть сколько ключей в домене содержат нашу маркерную фразу.
Правильный подбор конкурентов важен на этапе разработки. Ведь формировать структуру и продумать качественно функционал сайта лучше, учитывая опыт конкурентов, уже занявших высокие позиции в поиске. Этот список конкурентов можно экспортировать и работать в дальнейшем с файлом. На этом поиск семантики завершен.
Возвращаемся к проекту пакетного анализа.
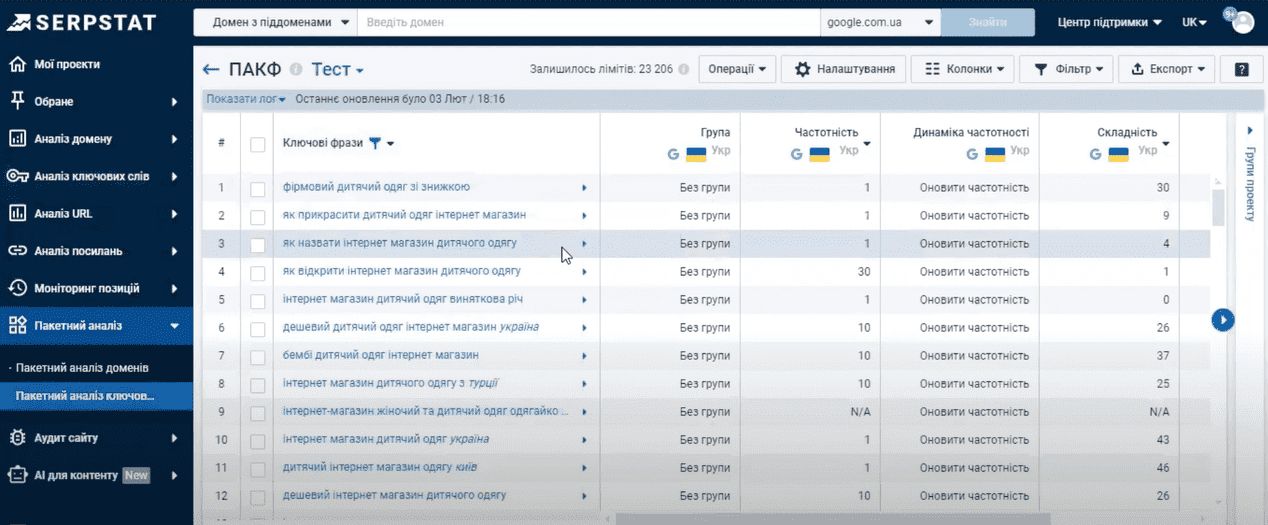
В нем сохранены все ключи, которые мы собрали в различных отчетах. Мы можем его просто экспортировать и использовать по своему усмотрению. Но, чтобы сформировать качественное семантическое ядро, необходимо провести кластеризацию запросов. То есть распределить все наши ключевые слова по группам, которые в дальнейшем будут формировать иерархию нашего сайта.
- Кластеризацию можно выполнить вручную.
Для этого на странице проекта пакетного анализа создаем группу, отмечаем необходимые фразы и добавляем их в группу. Кликаем «Добавить группу», даем ей название, далее – «Ок», выбираем фразы, затем кнопка «Операции» и «Добавить в группу», после чего выбираем нашу группу и «Применить». Готово.
- Другой вариант – автоматическая кластеризация.
Для этого выбираем все наши фразы, открываем «Операции» и кликаем на «Добавить фразы к кластеризации». Нам открывается окно с проектами. Кликаем «Создать новый проект». Вводим название нашего проекта. Домен вводим, если у нас уже есть сайт, если нет – оставляем пустым. Выбираем поисковую систему, регион. Область и город выбираем по необходимости. В нашем примере мы продвигаемся по Украине, так что оставляем не заполненным.
Сила связи – это условие кластеризации, где сильная – каждая фраза для объединения в кластер должна иметь 12 общих URL, а слабая – всего 3 общих URL.
Вторым условием формирования кластера является выбор типа кластеризации:
– мягкий тип – фразы могут быть добавлены в кластер, если хотя бы у одной пары из фраз есть 3, 8 или 12 одинаковых URL (в зависимости от предварительного выбора силы связи).
– жесткий тип – у всех фраз в одном кластере будут одинаковые 3, 8 или 12 URL в топ-30 по фразе (в зависимости от предварительного выбора силы связи). Результатом такого метода является точное ядро с большим количеством групп, так как фразы входят в кластер только при ярко выраженной смысловой близости.
К примеру, оставим параметры по умолчанию и нажимаем кнопку «Сохранить».
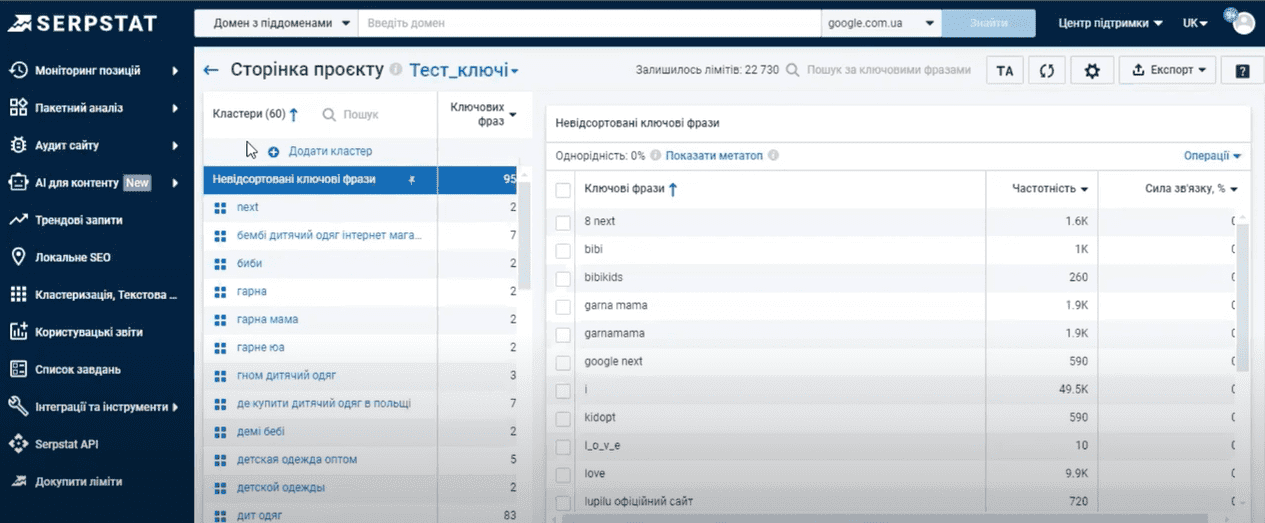
Мы видим, что наши фразы разбиты на отдельные группы/кластеры. Можем увидеть список ключей по каждой группе, процент однородности, а также есть функционал метатопов. Это список страниц конкурентов в поиске по фразам кластера. Чем выше страница в метатопе, тем релевантнее тематике кластера.
Теперь мы можем скачать наше готовое семантическое ядро отдельным файлом. Выгрузить можно как все ядро, так и отдельные кластеры, нажав «Экспорт» – выбрать нужный формат – «Экспорт». Готово.
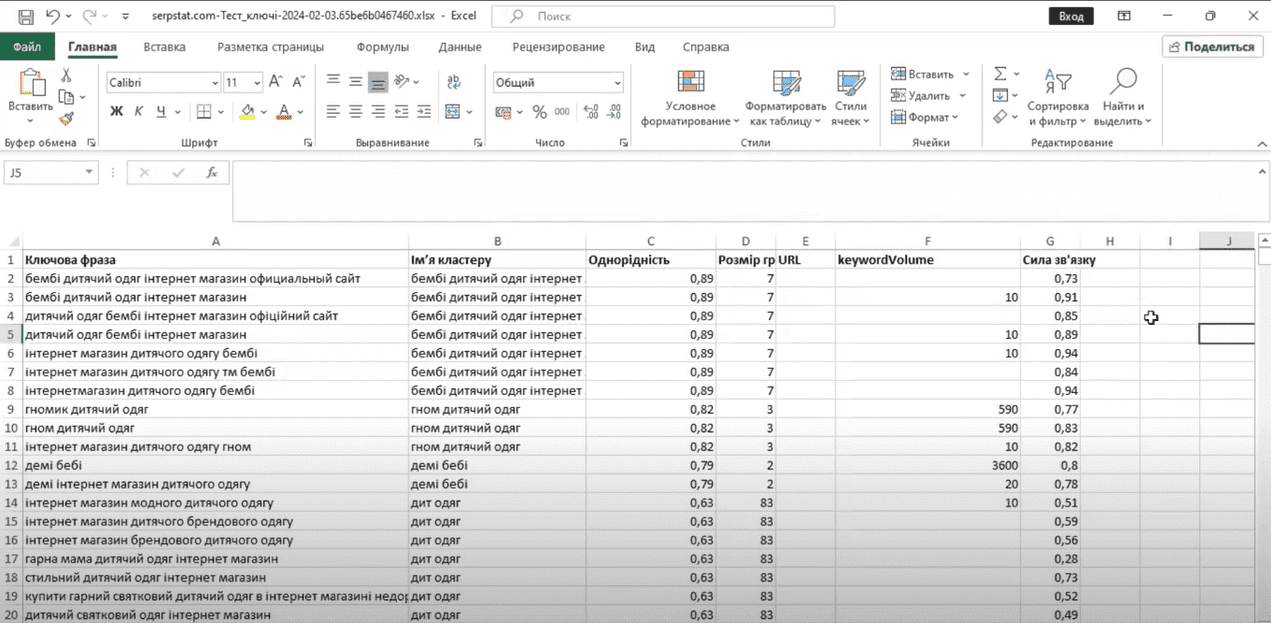
Так выглядит готовое семантическое ядро. Мы видим список фраз, название группы кластера и частотность.
Подведем итоги
В статье мы рассмотрели преимущества и недостатки инструмента, а также предоставили пошаговую инструкцию по подбору ключевых слов. Serpstat вполне может заменить почти любой другой сервис для SEO-специалистов и является действительно хорошим вариантом как для новичка, так и для профессионала.

коммерческое предложение
Другие статьи автора

01/08/2024
CPС или cost per click - это рекламная модель, которая позволяет маркетологам платить только тогда, когда их рекламу действительно видели и с ней взаимодействовали, а не за рекламу, которую можно проигнорировать.

22/12/2023
Показатель отказов на сайте является поведенческим фактором ранжирования, а соответственно, он оказывает влияние на SEO. Если показатель слишком высок, поисковики поймут, что ресурс оптимизирован недостаточно хорошо, и его можно не показывать, так как пользователям он не нравится.

07/10/2024
Медиапланирование помогает выявить рекламные каналы, которые стоит привлечь, прописать количество инвестиций, необходимых для реализации плана, график выхода объявлений и прочее, о чем подробнее поговорим далее. Планирование необходимо, чтобы заранее знать, какой будет результат рекламы и каким образом будет работать вся концепция.
Последние статьи по #SEO

26/03/2026
Преимущества интеграции ИИ в PPC-процессы не сводятся лишь к «более быстрой генерации текстов». Речь идет о системном изменении подхода.

23/03/2026
Инструменты на основе искусственного интеллекта уже не являются экспериментом. Сегодня они стали частью повседневной работы многих PPC-команд.

25/02/2026
UTM-метки – это специальные параметры, которые добавляются к обычной ссылке на сайт после вопросительного знака. Они не меняют страницу пользователя, но передают в системы аналитики информацию о том, откуда именно пришел трафик: с какой кампании, канала или объявления.