
 11/09/2024
11/09/2024  5893
5893


Інтернет-маркетинг
простою мовою
Content of the article
- /01 How does the web archive work?
- /02 Practical use of the web archive
- /03 How else can you work with the web archive?
- /04 How to save the current version of the site in the web archive?
- /05 How to prevent a site from being added to the web archive?
- /06 How to restore a site from a web archive?
- /07 To summarize

What is a web archive and how does it work?
Web archive (or web archive) is a service that allows you to store and reproduce different versions of web pages for different periods of time. One of the most well-known and widely used web archives is the Web Archive and its Wayback Machine tool. This archive aims to preserve the history of the Internet by providing access to older versions of websites that may have been modified or removed.
The history of the creation of the Web Archive and the Wayback Machine
The Internet Archive was founded in 1996 by Brewster Keil, an American librarian and entrepreneur. The goal of this project is to create a digital library that will store all the knowledge of humanity in free access. The service, launched in 2001, has become one of the key tools of the Internet Archive, which provides the ability to view archived copies of web pages.
How does the web archive work?
Web Archive works by regularly saving copies of web pages from different sites. These copies are stored in a format that allows users to reproduce them in the future. The process of saving web pages can be automatic or initiated by users.
The main stages of the web archive:
- Content collection. The Wayback Machine regularly scans the Internet and stores copies of available web pages. This process is called “crawling” (crawling) and includes saving the HTML code of the page, images, styles and other resources necessary for its reproduction. In addition to automatic crawling, users can also manually add pages to the archive using the Save Page Now tool.
- Storage and indexing. Once a page has been collected, it is stored on the Internet Archive’s servers. The page receives a unique URL in the format web.archive.org where users can view archived copies of web pages for specific dates.
- Playback of pages. When a user types a URL into the Wayback Machine search bar, the archive shows available versions of that page. Users can select a specific date and view how the page looked at that time. Reproduction occurs as close as possible to the original appearance, taking into account saved styles, images and other resources.
Practical use of the web archive
One of the key aspects of using a web archive is the ability to evaluate changes in the design, structure and content of a site, which helps to understand its evolution. It is useful both for analyzing competitors and for optimizing one’s own resources. Examining previous versions of resources allows you to discover effective strategies that have been used in the past.
Recovery of lost content through web archive
Another important function of web archive is the ability to restore lost content. In situations where the site has been hacked or its pages have been accidentally deleted, the web archive becomes a source for restoring the necessary information. This is especially useful for blogs, online stores or information resources where old content may still be relevant to the audience. With the help of the web archive, you can find and restore articles, product descriptions or other valuable materials.
Domain history analysis (history) before purchase
Before buying a new domain, it is important to conduct a detailed analysis of its history. Using the web archive, you can find out how the domain was used in the past: what topics it had, whether it was associated with questionable practices or spam. Such an analysis helps to avoid the risks associated with the acquisition of a domain that may have a negative reputation or history that will affect its SEO performance.
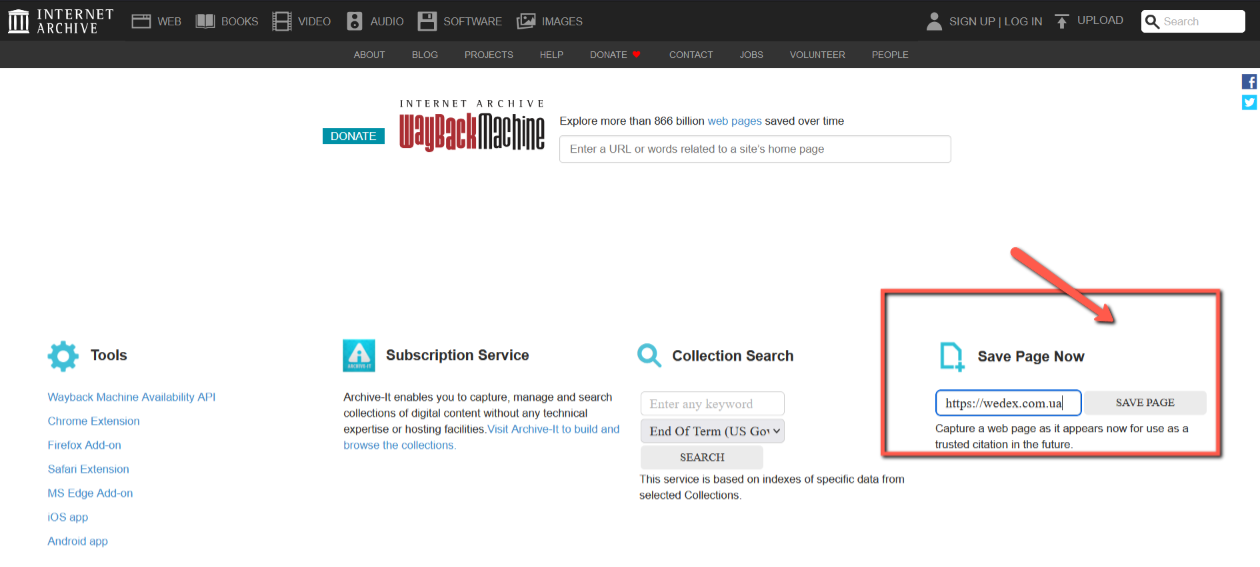
To start working with the tool, first you need to go to the link – https://web.archive.org/. This is the main page of the web archive.
To view the archive data of a certain site, its url address must be entered in the search bar.
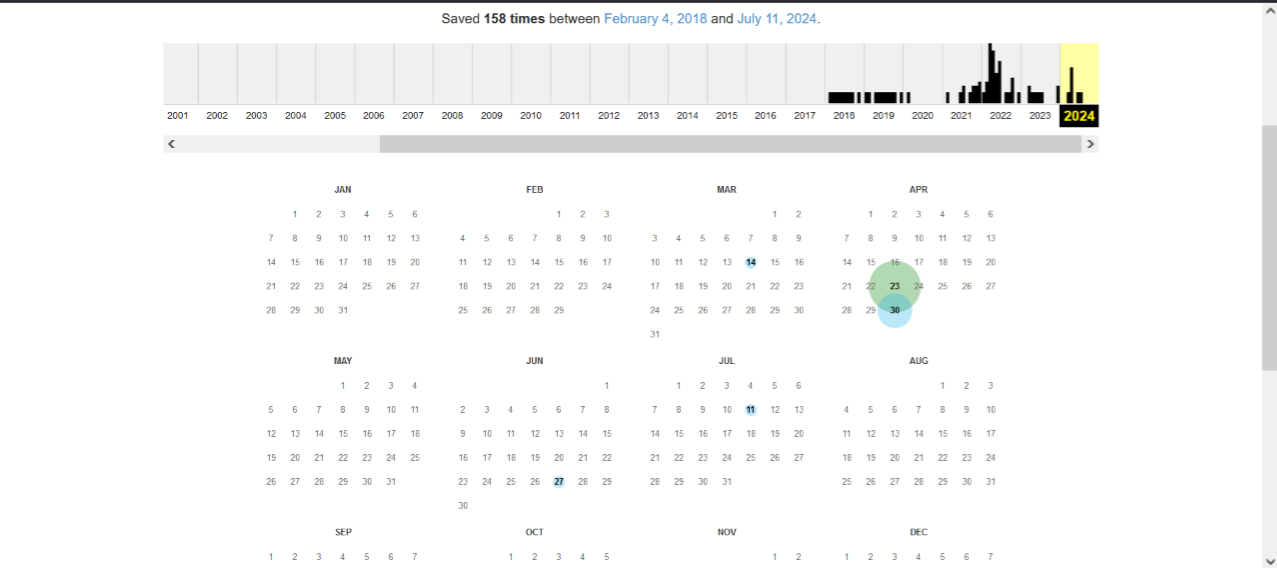
What you can see in the image:
- Website address. The address is entered on the screen “https://wedex.com.ua/” in the Wayback Machine search bar.
- Number of saved versions. The site saved 158 versions between February 4, 2018 and July 11, 2024.
- Archiving schedule. The upper part of the image shows a graph showing the years from 2001 to 2024. This graph shows the number of saved versions for each year. The most active conservation was in the period from 2021 to 2024.
- Calendar. Below is a calendar for the year 2024, where you can see which specific dates the versions of the site were saved. For example, it was stored on July 11, 2024, April 30, 2024, and other dates.
You are probably wondering: what are these colored circles on the numbers, and why do they have different sizes? These “circles” can be called “markers” in another word. They are marked with one of four colors:
- blue color indicates that the webcrawler received a response with code 200 OK, that is, the resource worked stably;
- the green color indicates the code 3xx — a redirect was configured on the site when the copy was created;
- orange and red colors indicate that the web resource was not available and the web crawler received a 4xx or 5xx error code.
The size of the circle depends on the number of web archive robot requests to the page that day. The larger the circle, the more copies were created by the web crawler.
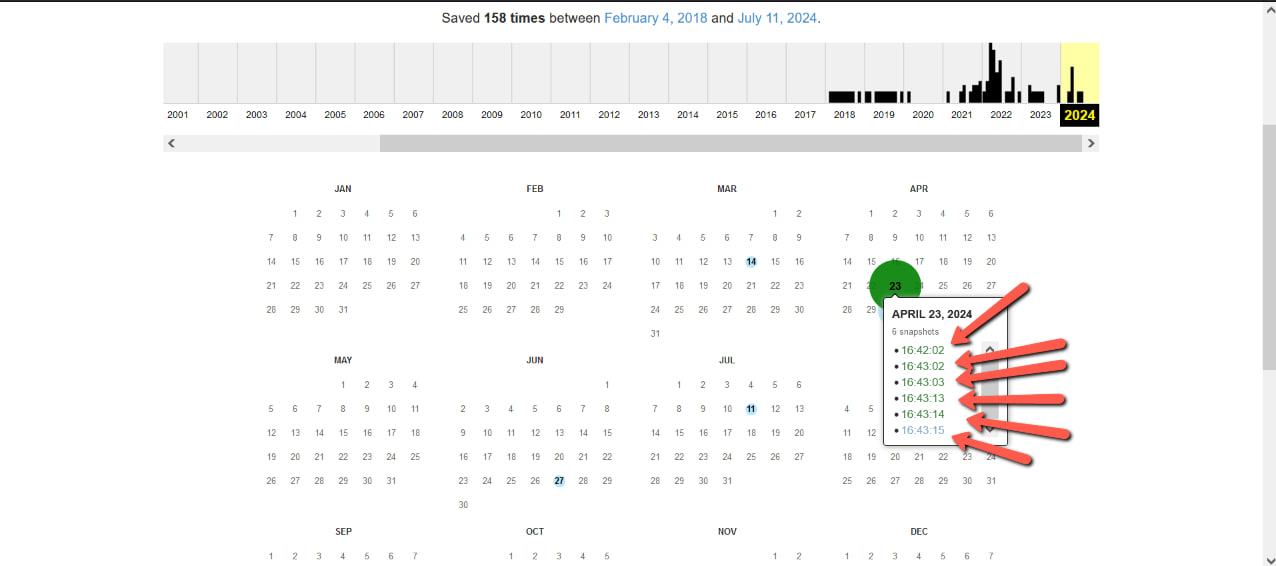
Let’s say you want to view the archive of the web page for April 23, 2024. Just hover over this number and select the version you want from the list.
In addition to the link, you can write a keyword in the search bar – then you will be able to get a list of sites that are promoted by it.
How else can you work with the web archive?
This service has several additional functions. To access them, just click on what you need.
Collections (Collections):
- this tab provides access to the various subject collections that are compiled in the Internet Archive. These may include archives of certain websites, subject collections, documents, multimedia and other types of digital content.
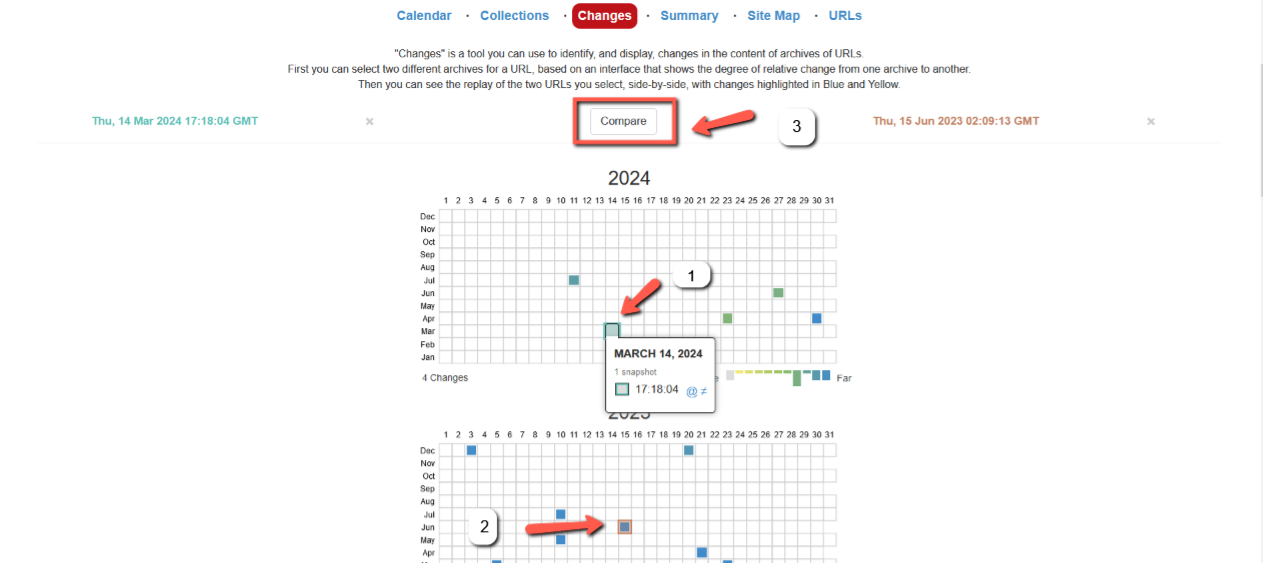
Changes (Changes):
- the “Changes” tab shows what changes have been recorded on the portal over time. Here you can see a comparison of different versions of web pages and understand exactly which elements on the page have changed. To see the comparison, you need to select the snapshots of the site for the period you need and click on the “Compare” button.
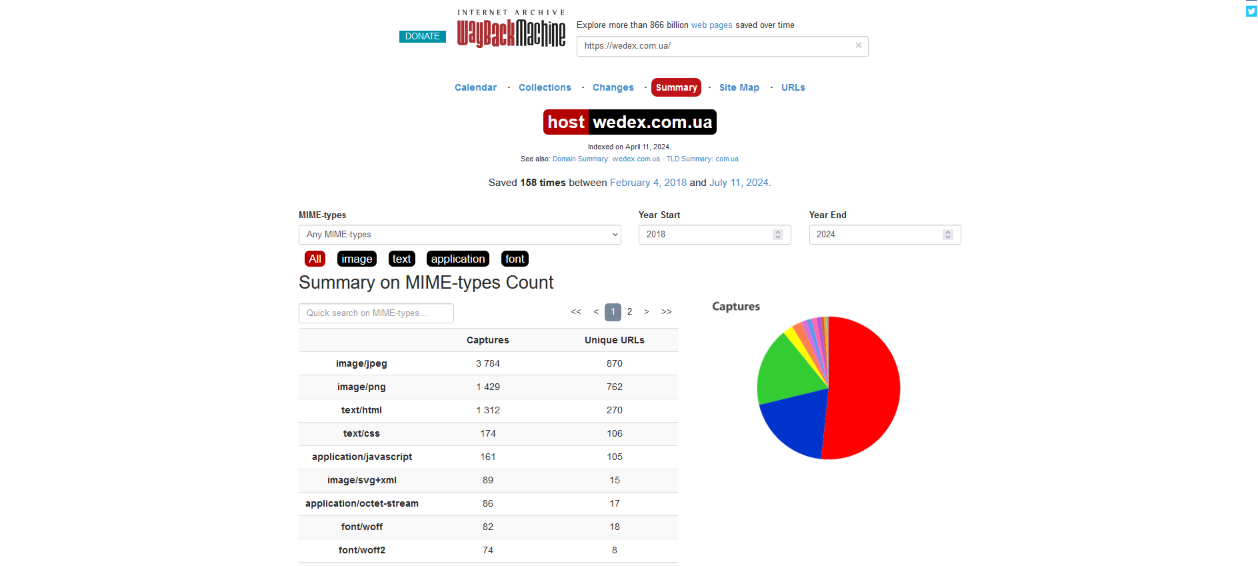
Summary (Summary):
- this tab provides an overview of the site’s archiving history. Here you can find general statistics such as the number of page copies saved, web crawler activity on the site and other important information.
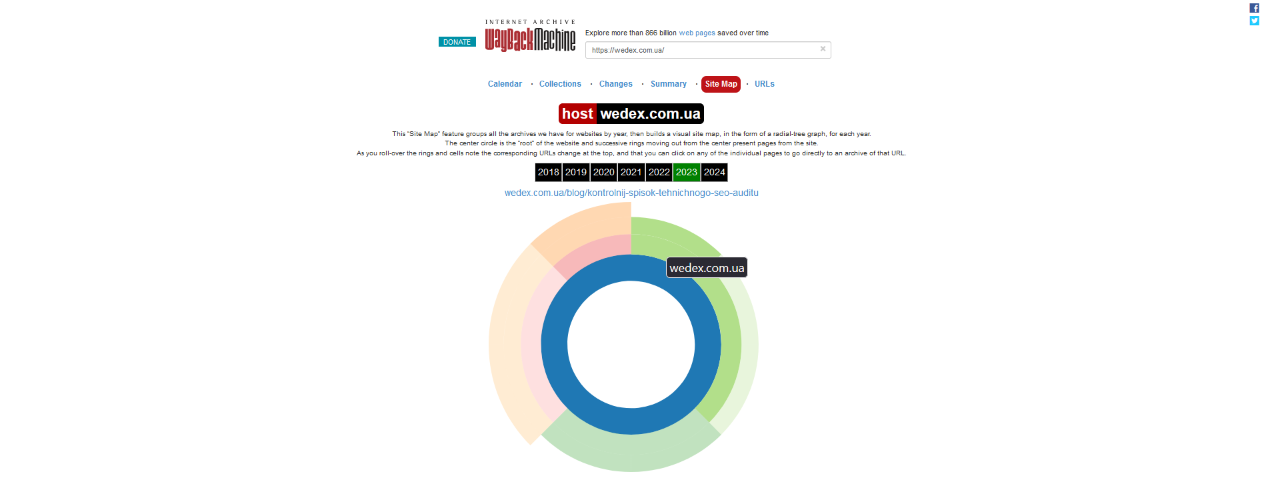
Site Map (Site map):
- this tab provides a structured map of the saved resource. It allows you to see how the pages on the site are organized and quickly go to the desired section or page.
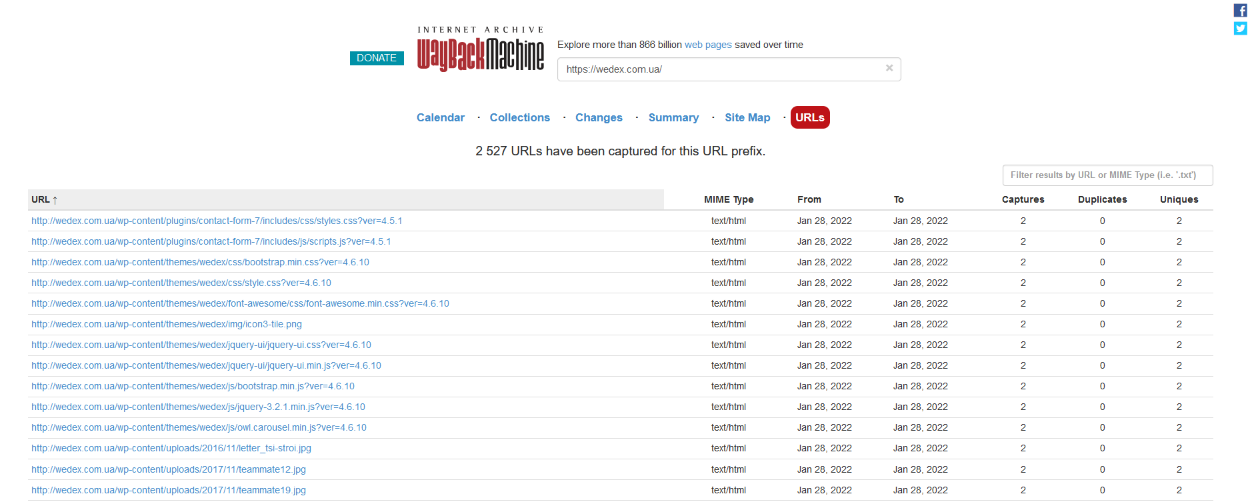
URLs:
- the “URLs” tab shows a list of all saved URLs in the portal that have been archived. This allows you to view specific pages or resources that have been archived.
How to save the current version of the site in the web archive?
Saving the current version of the site in the web archive is a fairly simple process. To do this, go to the Internet Wayback Machine and enter the URL of the website you want to save. After that, click the “Save Page Now” button, and your site will be added to archive org web. This will keep an up-to-date version of it for future use, which can be useful for tracking changes or saving important content.
How to prevent a site from being added to the web archive?
If you:
- are concerned that older versions of your web pages may contain sensitive information that should not be available to the general public;
- do not want someone to use your content for their own purposes;
- want to remove personal information from open access – It is necessary to prohibit the addition of a web resource.
There are 2 ways to do it.
The first is to contact its support service. If you contact support, all existing information about your site will be removed from the Internet Archive and web crawlers will not crawl it in the future.
To request complete removal of your site from the Web Archive, send an email to info@archive.org, specifying the domain name of your site in the message.
The second is to add a record to the file robots.txt. Only with this method there is one nuance – the robots.txt file only allows you to hide content from web crawlers. This means that robots will not scan your site and, accordingly, the information will not enter the archive, but the material that existed before the ban will be preserved and users will be able to see how the resource looked before.
Below is an example query for a robots.txt file:
User-agent: ia_archiver
Disallow: /
User-agent: ia_archiver-web.archive.org
Disallow: /
It is important that the file is in the root directory of your domain!
How to restore a site from a web archive?
Restoring a site from a web archive can be useful if your web portal has been deleted or lost some content. To do this, it is enough to find the appropriate version of the site in the Internet Wayback Machine and copy the required content or structure manually. Although this is not a full recovery because the server scripts and databases are missing, you will be able to recover static content and some important design elements of the resource. You can also copy the content using a script or contact the relevant services.
- Manual copying
This method takes a lot of time, because the web archive does not have a backup function for the entire site. You will have to manually copy each page of the site and save it in text editors. However, this method allows you to preserve the header structure, images, and even the basic style of the page. You can copy the content using the Ctrl+C, Ctrl+V command or press the F12 button and copy the program code.
- Copying using scripts
There are various Python scripts that automate the process of downloading content from the Wayback Machine. Some of the popular scripts are: wayback-machine-downloader, Wayback Machine Scraper, Wayback Scraper. To use them, you must first install the necessary tools, such as Python, and install the script via a package manager (eg pip). The linked README file has step-by-step instructions for installation and next steps. This will greatly help to optimize time and work.
- Use of third-party services
This service will already be paid, because you will have to contact organizations or specialized sites. The most popular services are Archivarix, Wayback Machine Downloader.
To summarize
Web archive is an indispensable tool for saving and viewing historical versions of websites. With the help of the Internet Wayback Machine, you can easily check how the site has changed over time, save its current version or even restore lost data. At the same time, if there is a need to protect your site from archiving, there are methods to prevent it from being added to the web archive. Mastering these skills will help you effectively manage your resource and ensure the preservation of important digital history.

commercial offer
Other articles by the author
11/09/2024
A web archive is a service that allows you to store and reproduce different versions of web pages for different periods of time. One of the most famous and widely used web archives is Web Archive and its Wayback Machine tool.

07/05/2024
Internet marketing is one of the most effective tools for promoting services and goods. With the skillful use of the entire range of available methods and different types of channels, a successful strategy can bring a business to a qualitatively new level, guaranteeing stable development and achievement of the most ambitious goals.

11/08/2023
Business exists in a constantly competitive environment, so for its successful development, it is necessary to take into account the strengths of the enterprise, risks, and various factors of influence. This is exactly what SWOT analysis helps with. In this article, we will tell you what a SWOT analysis is, why and how it is conducted, and provide examples of it.
Latest articles by #SEO

29/05/2026
A virtual SMS number is ideal for businesses that handle a high volume of inquiries, operate across multiple markets, and require in-depth analytics and reporting.
08/05/2026
Influencer marketing for businesses is not just a way to draw attention to a brand. When part of a well-designed strategy, it helps achieve multiple objectives at once.

06/05/2026
A workshop is an interactive, hands-on session during which participants listen to an expert and work together on a specific task.