
 25/05/2024
25/05/2024  4675
4675


Інтернет-маркетинг
простою мовою
Content of the article

Website indexing and methods of influencing it
Website indexing is the process of crawling a website and adding it to the search engine database in a special form. Therefore, those pages that are in the search results are called indexed. This process is very important for work and website promotion, because with incorrect instructions to search robots, pages with personal data, duplicates and other garbage pages may appear in the results.
During the indexing process, crawlers collect data from resource pages, evaluate content (text and graphic), link mass, meta tags and structure. The final result depends on the overall quality of website optimization (external and internal). The more “points” a certain page receives during verification, the higher it will be displayed in search results.
Website indexing also plays a big role for website owners because it makes it possible to attract new users and increase resource traffic. The more web pages are indexed in a search engine, the higher the likelihood of attracting the target audience and increasing organic traffic.
Adding a site to the search engine index
In order for the search engine to know about the appearance of a new site, it needs to be notified about it in a special way. There are several ways to do this, which may differ in speed or efficiency. Let’s look at them below.
Adding with the URL checker tool in Google Search Console
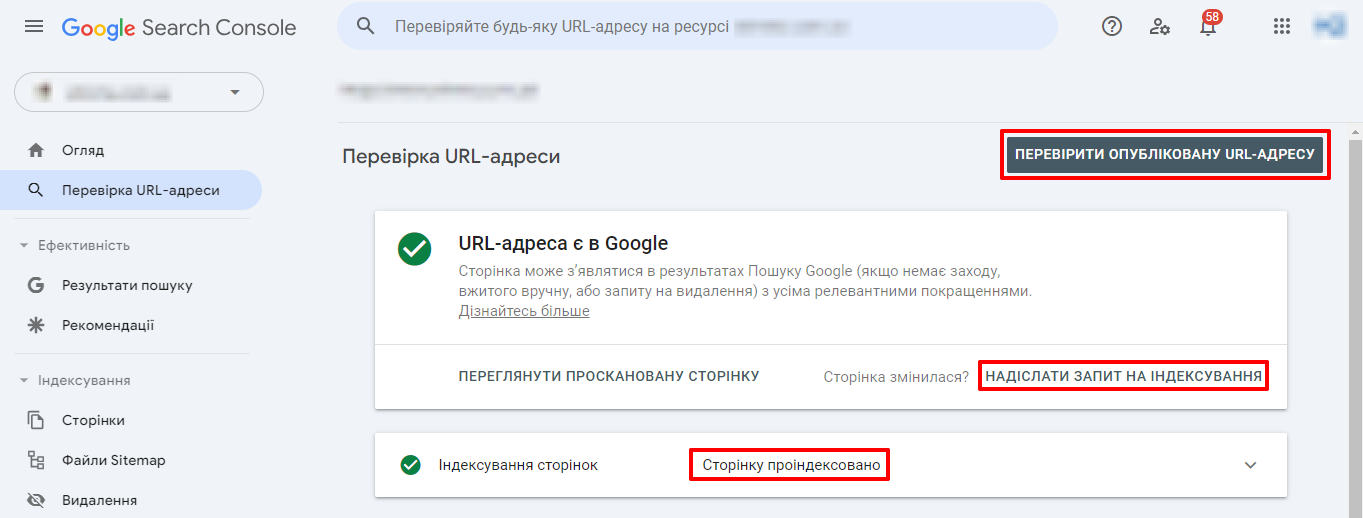
This tool allows the GSC to request that a page be indexed by a search engine and to know where the process stands (which can take from one day to 2 weeks). It should be taken into account that in one day you can send up to 10 requests for indexing, and sending such a request does not guarantee that the page will appear in the Google index.
To test it, you paste the site address into the line:
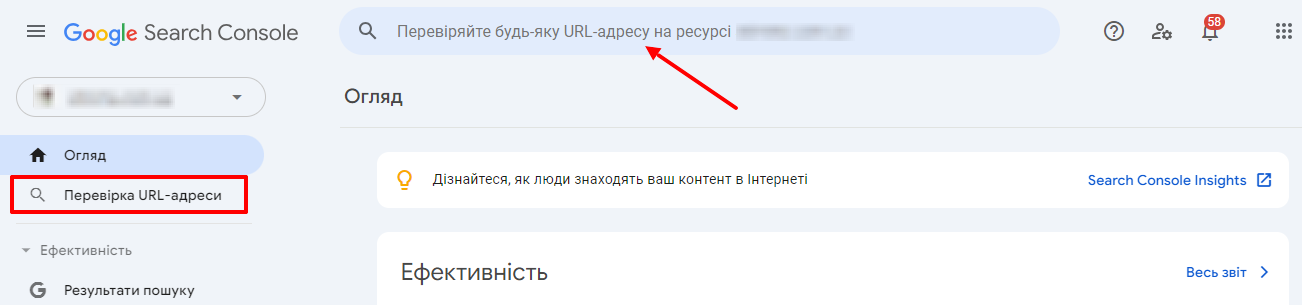
Then click on “Check published URL”. And if it is not yet in the index, click “Request Indexing”. And in the event that no errors are detected, the page will be added to the queue.
Adding an external link to your site
This method is that on a certain resource that has good indexing, you place a link to your site, and crawlers, when crawling the donor site, will see a link to an unindexed site and add it to the queue. It is best to post on popular information or news portals, since most often they have robots visiting the site every 2-3 hours. This method of adding a site is less fast and less reliable, but still effective.
Adding an external link from social networks
This method became quite relevant several years ago, when the search engine began to fully evaluate social network pages as full-fledged resources. You just need to add a link to the site. But a very important nuance is that the link must be direct, since a link through a redirect will not give any result.
Site indexability: how to find out
To understand how effectively a site is indexed, you need to know the number of pages on the site that need to be indexed, and the pages that have already been crawled by robots.
I= N1 (indexed pages) / N2 (all necessary site pages) * 100%
The value of variable N1 can be found in several ways:
- by inserting the following code “site:site.ua” into the search bar and scrolling to the last page of the search results, see the actual number of pages in the index. This must be done separately for each search engine.
- the second method is only suitable for Google. You can see the number of indexed pages in SearchConsole in the “Indexing” section, “Pages” subsection, the number of indexed pages is indicated there.
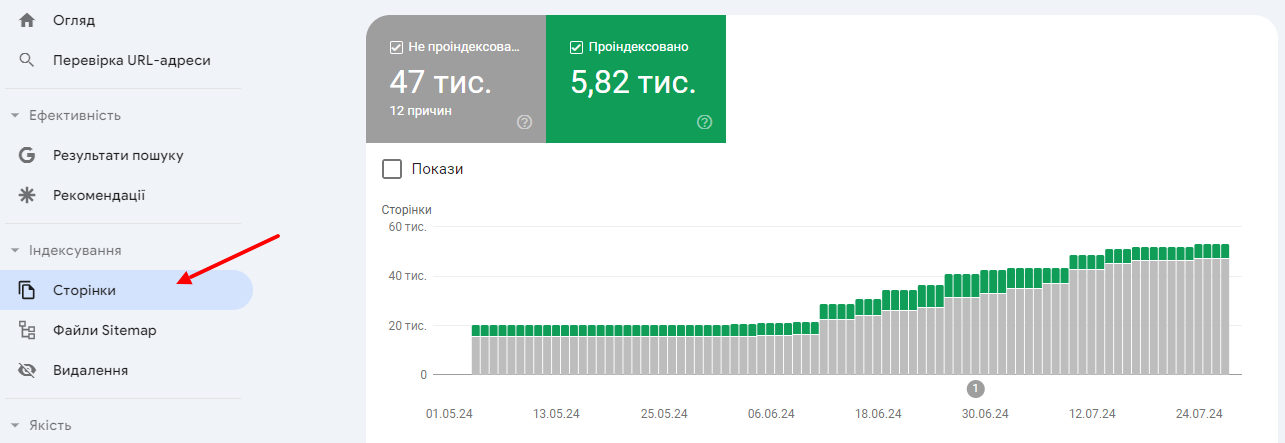
The value of variable N2 can be recalculated:
- by the number of addresses in the site map;
- by the number of addresses in the site upload after removing junk pages.
For example: there are 330 indexed pages in Google. And there are 350 pages in total on the site. Then it turns out like this:
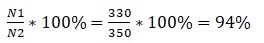
If the indexation percentage is less than 50%, then this is a very bad indicator and means that the site has big problems with indexing, and an in-depth analysis of the reasons is needed.
If the indicator ranges from 50% to 80%, then the site has minor problems with indexing and, most likely, this is due to incorrect settings of robots.txt and sitemap.xml.
If the indicator ranges from 80% to 100%, then the site’s indexing is normal. And there is no need to make any drastic changes.
If this ratio is more than 100%, then most likely the site has problems with incorrect robots.txt settings or an incomplete site map.
How to improve site indexability?
In order to speed up site indexing as much as possible, it is necessary to correctly configure the site’s interaction with search robots, and very clearly show them what needs to be crawled and what not. Various methods and functionality are used for this. There are 3 available methods to prohibit indexing; we will discuss each separately below. In order to show robots what needs to be indexed, special lists of addresses are compiled, called site maps; we will also describe them below.
Robots.txt file
Using directives in the file, you can give recommendations to search robots about what should be indexed and what not. But the pages closed in robots.txt, may appear in the results, since the instructions are advisory in nature when crawling the pages. Also, if garbage pages appear in the search results, you won’t be able to delete them; you just need to put them in the “snot” (Supplemental index or results) – an additional Google search with low-quality pages. To ensure that pages disappear from the index and crawlers do not index them, it is necessary to use other methods.
Using the correct basic instructions in the robots.txt file makes it possible to monitor the indexing process and increase the accessibility and visibility of your resource in the search engine. This is one of the main tools for optimizing a website and getting good results in search results.
META tag “Robots”
This method of closing pages from indexing robots is no longer a recommendation, but a mandatory one. Using meta robots you can remove pages from search results, which robots.txt did not allow. Also, using this tag, you can not only control the indexing of content, but also the transitions to internal and external links.
List of directives that apply:
- Index – gives permission to index the page
- Noindex – blocks robots from accessing the page
- Follow – allows you to follow all links on the page
- Nofollow – prohibits clicking on hyperlinks
- All – allows indexing and following links
- None – prohibits crawling the page and following links
That is:
<meta name=“robots” content=“index,follow”> = <meta name=“robots” content=“all”>– indexing and transitions are allowed;
<meta name=“robots” content=“noindex,follow”>– you cannot download page content, but you can follow links;
<meta name=“robots” content=“index,nofollow”>– you can load page content, but transitions are prohibited;
<meta name=“robots” content=“noindex,nofollow”> = <meta name=“robots” content=“none”>– everything is prohibited.
Using the X-Robots-Tag http header
This control method is the most advanced and most flexible, since it gives instructions for working with the page immediately when loading the server’s http response. The peculiarity is that it is used not only for html pages, but also for any files: pictures, videos, documents, etc. Using meta robots, you can only close HTML pages.
The X-Robots-Tag has the same directives as the robots’ meta tag:
- index;
- noindex;
- follow;
- nofollow;
- all.
Indexing pages using a sitemap
Site Map is a file with a list of all site pages that should be indexed and added to search results. With the help of this site, the work of the search robot is simplified. He will not just follow internal links, wasting time, crawling budget and server capacity, but will visit exactly those pages that are indicated in the site map.
It is also very important that the sitemap can indicate the crawl priority and the date of last modification. These are very important parameters for a large site or resource with constantly changing content. For example, if the editing date (<lastmod>) is specified, why should the robot re-crawl pages that have not changed since the last time? It is better to unload those on which the content has changed. Or if a priority is specified (<priority>), then the crawler will crawl pages with a higher priority first, all other things being equal.
For example, we have a sitemap like this:
URL1
2018-01-02T12:41:56+01:00
1.0
URL2
2018-01-02T12:41:56+01:00
0.8
URL3
2018-01-05T12:41:56+01:00
0.8
Then page URL3 will be indexed first (the last one to change), followed by URL1 (since priority 1).
Preparing and submitting a sitemap is a significant strategy to speed up and simplify the process of indexing your web resource by search engines. Updating your sitemap with consistent regularity also ensures that you can monitor your site’s presence in search results and increase its visibility to users.
To summarize
In the article we looked at what indexing is and methods for improving it. As we review the topic, it becomes clear that the number of indexed pages directly affects the attraction of the target audience and organic traffic. Optimizing your content, improving your site structure, and using the right meta tags will help your pages be more fully indexed by search engines. Understanding these aspects will help a website compete effectively in the online space and attract its target audience through increased visibility in search results.

commercial offer
Other articles by the author
25/05/2024
Website indexing is the process of crawling a website by crawlers and adding it to the search engine database in a special form. Therefore, those pages that are in the search results are called indexed. This process is very important for the operation and promotion of the site.

12/10/2023
Google provides a very wide range of options for customizing and supplementing your ads. This allows you to design the appearance of your ad snippets in a very beautiful and unique way and to reveal your USP (unique selling proposition) even more widely, which can improve the click-through rate of your ad several times, so you shouldn't neglect the settings of the add-ons, especially since filling them out doesn't require titanic efforts.

07/01/2026
Decomposition is the systematic breakdown of a large, often abstract goal into a set of interrelated, clearly defined subgoals and tasks.
Latest articles by #SEO

12/06/2026
In professional circles, UX refers to the entire ecosystem of human interaction with a brand, digital product, or service.

02/06/2026
The best specialists are those who can see the real problems faced by clients and the needs of the business behind the lines of code.
29/05/2026
In a business context, Telegram Premium isn't just a status symbol—it's a set of features that make communication faster, more intuitive, and more convenient for customers.