
 17/05/2024
17/05/2024  4974
4974


Інтернет-маркетинг
простою мовою
Зміст статті

Як скласти файл robots.txt?
Файл robots.txt – це спеціальний індексний файл, призначений для вказівки пошуковим роботам на те, що можна індексувати на сайті, а що не можна. Але як було написано у попередній нашій статті, для закриття деяких сторінок на сайті потрібно застосовувати інші способи, поговоримо про них далі.
Звичайно, можна вбити пошуковий запит «стандартний файл robots.txt» і, знаючи адмінку, на якій написаний сайт, завантажити його з інтернету. Але кожен сайт є унікальним і те, що підходить одному, не обов’язково підходить іншому. Саме тому необхідно індексний файл створювати індивідуально для кожного сайту. Тоді ви точно будете впевнені, що робот правильно обходитиме сторінки.
Складання файлу robots.txt ми завжди починаємо з розвантаження сайту. Що це таке? Це спеціальний файл із усіма сторінками сайту та їх параметрами: url, title, description, тип, відповідь сервера, розмір тощо. Все це оформлено в окремому файлі у вигляді великої таблиці, деякі сервіси надають онлайн перегляд вивантаження. Програм для вивантаження та первинного аналізу сайту просто маса, не акцентуватимемося на них, щоб не робити реклами. Нам підійде будь-яка, яка вивантажує адресу сторінки, її тип та доступність.
Для чого потрібний файл robots.txt
Насамперед для того, щоб побачити повну кількість сторінок та файлів на сайті. Також за його допомогою добре видно шляхи розташування тих чи інших файлів та наявності сторінок сортувань, фільтрів та сторінок з динамічними параметрами. Практично всі сучасні програми показують, відкрито сторінку для індексування чи ні.
Потрібні доступи на ftp або хостинг, щоб переглянути структуру папок та каталогів. Чисто теоретично, роботс можна скласти і без доступів, знаючи адмінку сайту та приблизну внутрішню структуру сайту. Для того, щоб визначити адмінку, можна скористатися сервісом WhatCMS.
Ми практикуємо спосіб написання robots.txt за методом «закрий все – відкрий потрібне», таким чином ми мінімізуємо можливість потрапляння в пошукову видачу сміттєвих сторінок і файлів.
Складання файлу robots.txt
Нижче розглянемо поетапно, як правильно складати файл robots.txt.
Написання robots.txt
Перше, що нам потрібно зробити, – це створити на комп’ютері звичайний текстовий документ з ім’ям robots.txt і зберегти його в кодуванні utf-8. Регістр символів у назві має бути у всіх букв однаковий – нижній. Назва має бути не Robots.txt, не ROBOTS.txt – а саме robots.txt і ніяк інакше.
Прописуємо першу команду, яка вказує директиви на обхід чи ігнорування. Це команда User-agent. Після неї без пропуску необхідно поставити «:» (двокрапка), пропуск та ім’я конкретного робота або * (для всіх роботів). Розглянемо наш сайт wedex.com.ua.
У своїй практиці ми не поділяємо директиви під різні пошукові системи. Розділяти їх потрібно лише в тому випадку, коли вам необхідно для різних пошукових систем індексувати різні файли. Наприклад, якщо сайт потрапив в одній із пошукових систем під фільтр, а по іншій все відмінно, тоді не варто міняти сайт, краще скопіювати його на інший домен і виправити помилки – і таким чином у вас буде 2 сайти, які дають трафік кожен зі свого пошуковика.
Прописуємо Allow та Disallow
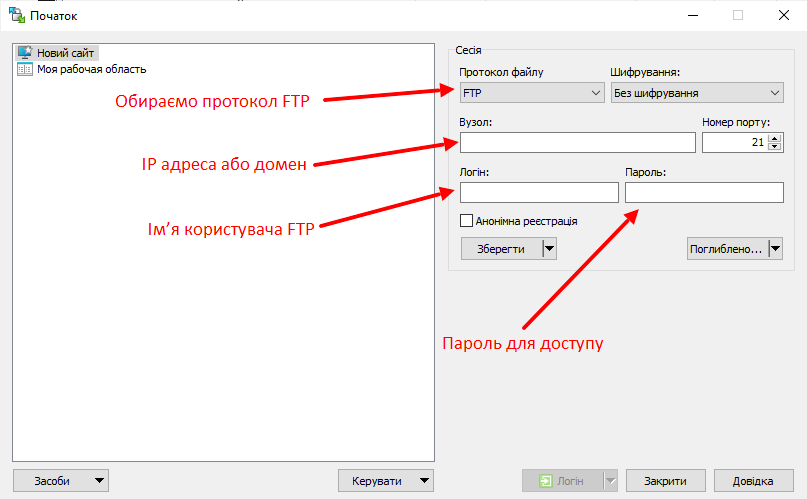
Далі заходимо на FTP. Зробити це можна або за допомогою TotalCommander, або за допомогою інших програм. Ми користуємося програмою WinSCP, тому що вона дозволяє вносити редагування у файли «на льоту».
Відкриваємо зручну для використання програму та заповнюємо дані для доступу до ftp сайту.
Якщо все зроблено правильно, побачите приблизно це:
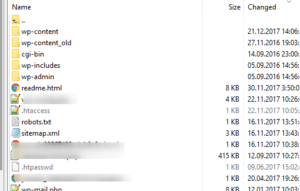
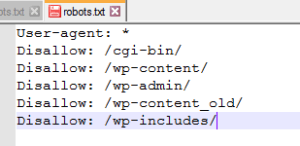
Копіюємо назву папок та закриваємо їх за допомогою директиви Disallow.

Виходить приблизно так:
Далі ми починаємо працювати з розвантаженням сайту. Нам потрібно перевірити, чи ми не закрили якісь важливі сторінки. Заходимо в Validator and Testing Tool для перевірки, заповнюємо всі необхідні дані та натискаємо «Test».

Додаємо адреси з вивантаження, які потрібно перевірити, закриті чи відкриті вони до індексації. Можна перевірити 1 url.
За зеленим написом «Allowed» нижче видно, що сторінка відкрита для індексації – це те, що нам потрібно.
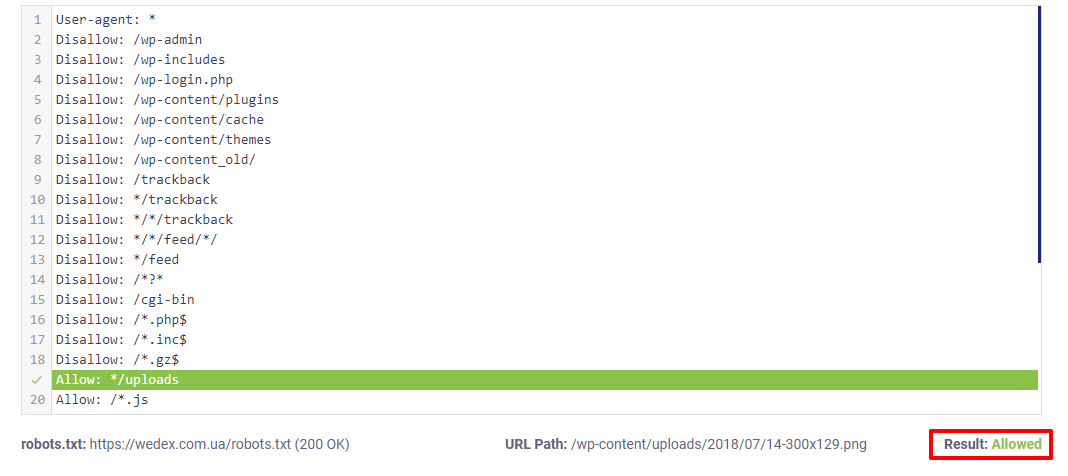
Далі за вимогами пошукових систем для індексації повинні бути відкриті всі java-скрипти, css-файли та картинки. Тому ми перевірятимемо кожен тип файлів так само, як перевіряли html сторінки.
Вибираємо адреси всіх файлів js у файлі вивантаження та перевіряємо їх доступність так, як показали вище. Якщо файли ява-скриптів закриті, їх потрібно відкрити. Знаходимо всі урли скриптів та шукаємо, як можна згрупувати.
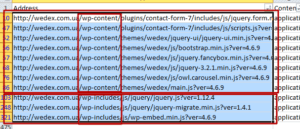
Групуємо по папках та розширеннях. Додаємо відповідні директиви Allow у файл роботса.
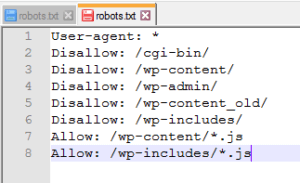
Перевіряємо їхню доступність після внесення правок.
Так ми чинимо з усіма файлами: стилів – css та картинок jpg, png, які у вас є на сайті, також можна дозволити індексацію унікальних pdf, doc, xml, та інших файлів у разі потреби. Дивимося, що в нас зрештою вийшло. Ще раз перевіряємо все, чи нічого зайвого не закрили, і йдемо далі.
Додаємо посилання на карту сайту
Ця директива може бути необов’язковою, якщо у вас немає карти сайту. Але все ж таки ми дуже рекомендуємо згенерувати карту сайту хоча б автоматичним сервісом або створити вручну.
Додаємо директиву Sitemap, ставимо двокрапку та пропуск і вставляємо посилання на карту вашого сайту. У нас карта сайту лежить у кореневому каталозі та має стандартну назву sitemap.xml. Тому ось що в нас вийшло зрештою.
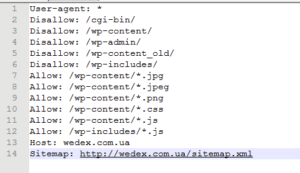
Додавання файлу robots.txt на сайт
Після того, як ви закінчили його складання, вам потрібно додати його до конової папки сайту. Це дуже просто. Зробити це можна через програму, якою ви дивилися папки на FTP.
Просто відкриваєте кореневу папку вашого сайту і перетягуєте туди новий роботс.
Перевірка в Google SearchConsole
У GSC можна перевірити, чи може Google обробити файли robots.txt. Для цього потрібно відкрити сервіс під своїм логіном, натиснути «Налаштування» – «Відкрити звіт».
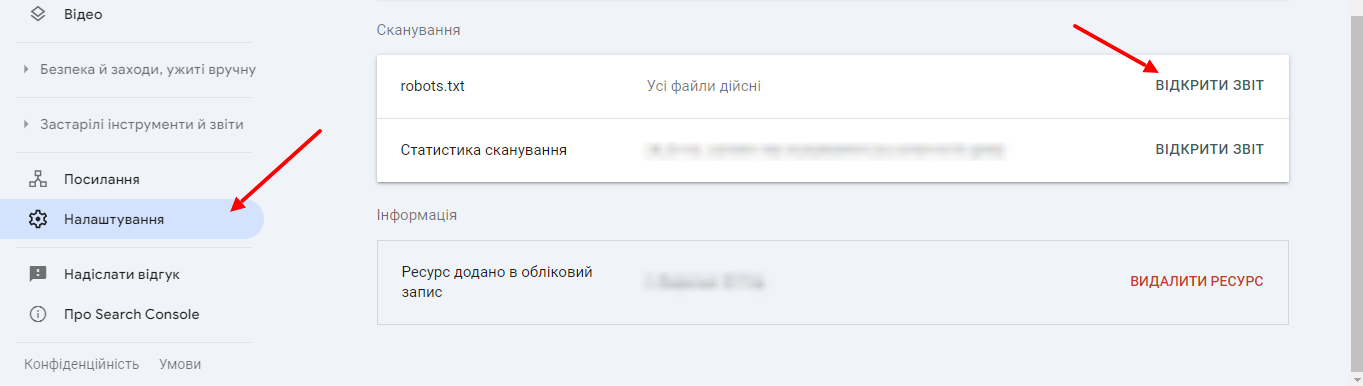
Тут ви побачите його параметри.
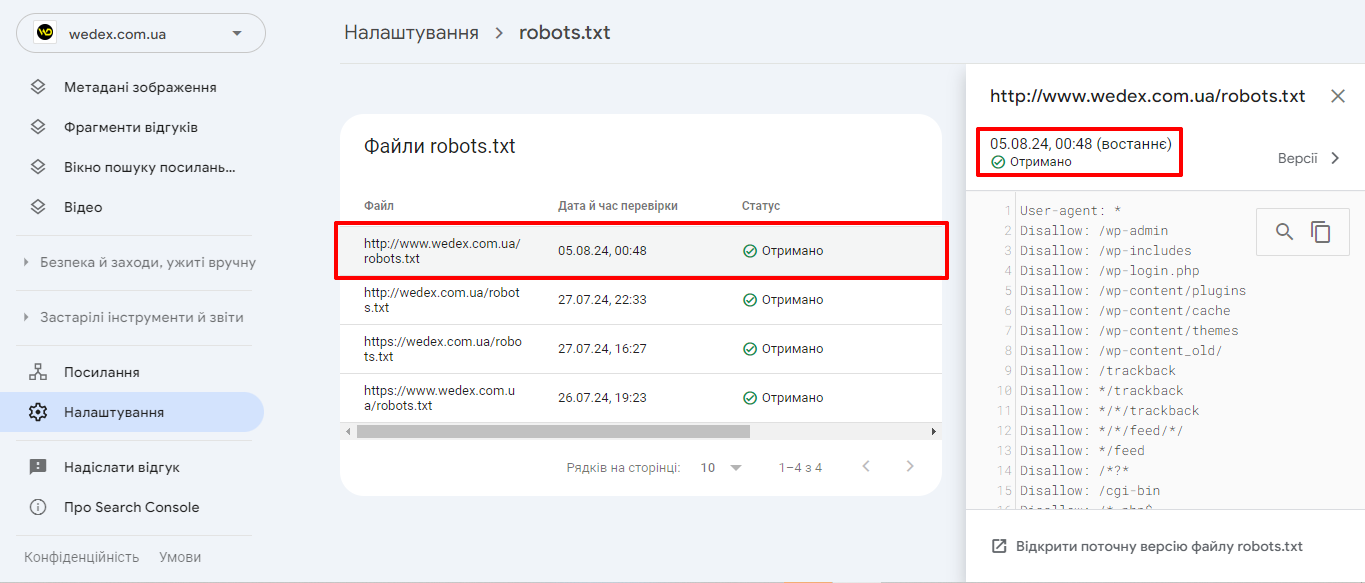
За звітом robots.txt можна побачити, які файли robots.txt Google знайшов для 20 найпопулярніших хостів на вашому сайті, час останнього сканування, а також будь-які попередження чи помилки.
Підведемо підсумки
Файл robots.txt є важливим інструментом, який відіграє ключову роль у взаємодії з пошуковими роботами і є невід’ємною частиною ефективного SEO. Він дозволяє контролювати процес індексації сайту та керувати доступом пошукових систем до певних сторінок. Правильне налаштування robots.txt може значно покращити видимість вашого сайту у пошуковій видачі.

комерційна пропозиція
Інші статті автора

24/04/2025
Завдяки концепції SaaS доступ до сучасних програм, оновлень application і технічної підтримки сайтів став простішим, що дало змогу прискорити процес впровадження інноваційних рішень на ринку України та за її межами.

08/08/2024
Типова комерційна пропозиція – це, як правило, лист (іншими словами текстовий документ), де описується продукт та умови для співпраці з вигодами для потенційного партнера або клієнта. Іноді використовують замість текстового аудіовізуальний формат, відео презентацію чи інше.

06/08/2025
Інтернет-фішинг — це одна з найпоширеніших сучасних схем шахрайства в інтернеті, що має єдину мету: отримати вашу конфіденційну інформацію.
Останні статті по #SEO

24/06/2026
IT-аутсорсинг — це передача частини ІТ-функцій зовнішній команді або компанії, яка бере на себе виконання визначеного обсягу робіт на умовах договору.

19/06/2026
Крауд-маркетинг — це розміщення корисних, нативних згадок про бренд, продукт або послугу на майданчиках, де вже спілкується ваша аудиторія.

18/06/2026
Директор з маркетингу — це насамперед топменеджер, який входить до складу вищого керівництва компанії і мислить категоріями бізнесу, а не окремих рекламних кампаній.