
 17/05/2024
17/05/2024  4867
4867


Інтернет-маркетинг
простою мовою
Content of the article

How to create a robots.txt file?
The robots.txt file is a special index file designed to indicate to search robots what can be indexed on a site and what cannot. But as was written in our previous article, to close some pages on the site you need to use other methods, we’ll talk about them later.
Of course, you can enter the search query “standard robots.txt file” and, knowing the admin panel on which the site is written, download it from the Internet. But every site is unique, and what works for one may not necessarily work for another. That is why it is necessary to create an index file individually for each site. Then you will be sure that the robot will crawl the pages correctly.
We always start compiling the robots.txt file by unloading the site. What is it? This is a special file with all the pages of the site and their parameters: url, title, description, type, server response, size, etc. All this is formatted in a separate file in the form of a large table; some services provide online viewing of the upload. There are simply a lot of programs for downloading and primary analysis of a site; we will not focus on them so as not to advertise. Any one that downloads the page address, its type and availability will suit us.
What is the robots.txt file for?
First of all, in order to see the full number of pages and files on the site. It also helps you clearly see the location of certain files and the presence of sorting pages, filters, and pages with dynamic parameters. Almost all modern programs show whether a page is open for indexing or not.
You need access to ftp or hosting to view the structure of folders and directories. Purely theoretically, robots can be created without access, knowing the site admin and the approximate internal structure of the site. In order to determine the admin panel, you can use the service WhatCMS.
We practice writing robots.txt using the “close everything – open what you need” method, thus minimizing the possibility of junk pages and files ending up in search results.
Compiling the robots.txt file
Below we will consider step by step how to correctly compose a robots.txt file.
Writing robots.txt
The first thing we need to do is create a regular text document on the computer named robots.txt and save it in utf-8 encoding. The case of characters in the name must be the same for all letters – lowercase. The name should not be Robots.txt, not ROBOTS.txt – namely robots.txt and nothing else.
We write the first command, which specifies directives to bypass or ignore. This is the User-agent command. After it, without a space, you need to put “:” (colon), a space and the name of a specific robot or * (for all robots). Let’s take a look at our site wedex.com.ua.
In our practice, we do not separate directives for different search engines. You only need to separate them if you need to index different files for different search engines. For example, if a site falls under a filter in one of the search engines, but everything is fine on the other, then you shouldn’t change the site, it’s better to copy it to another domain and correct the errors – and this way you will have 2 sites, each generating traffic from its own search engine.
We register Allow and Disallow
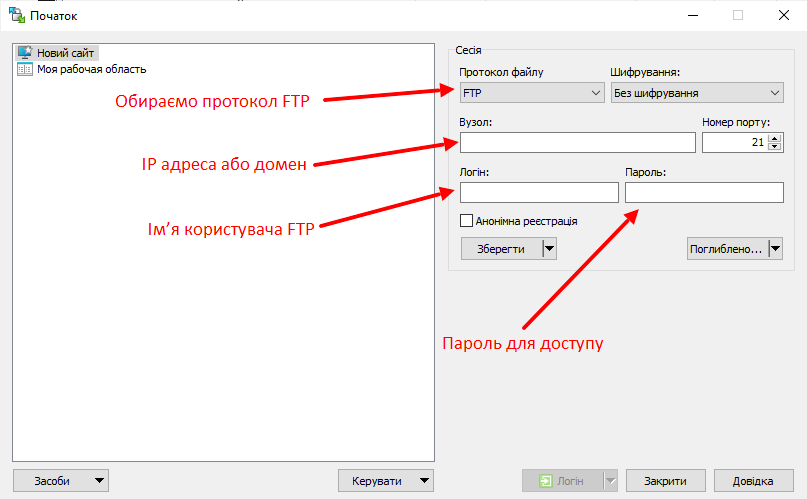
Next, go to ftp. This can be done either using TotalCommander or using other programs. We use WinSCP because it allows us to make changes to files on the fly.
Open an easy-to-use program and fill in the data to access the FTP site.
If everything is done correctly, you will see something like this:
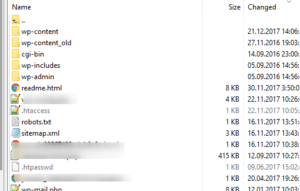
Copy the names of the folders and close them using the Disallow directive.

It turns out something like this:
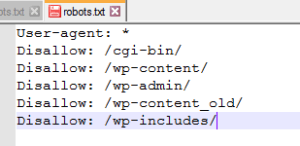
Next, we begin to work with unloading the site. We need to check if we have closed any important pages. Let’s go to Validator and Testing Tool to check, fill in all the necessary data and click “Test”.

Above we add addresses from the upload, which need to be checked whether they are closed or open to indexing. You can check 1 url.
The green “Allowed” inscription below shows that the page is open for indexing – this is what we need.
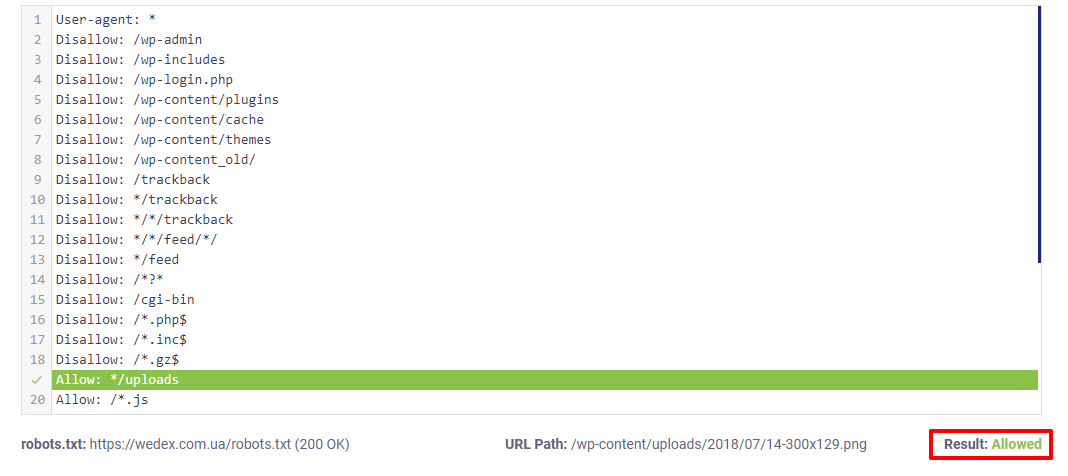
Further, according to the requirements of search engines, all java scripts, css files and images must be open for indexing. Therefore, we will check each file type in the same way as we checked html pages.
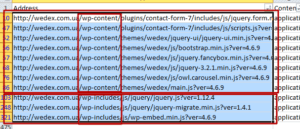
We select the addresses of all js files in the upload file and check their availability as shown above. If the Java script files are closed, you need to open them. We find all the script URLs and look for how we can group them.
We group by folders and extensions. Add the appropriate Allow directives to the robots file.
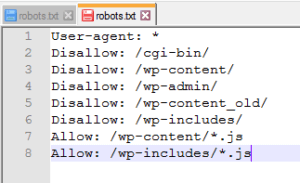
We check their availability after making changes.
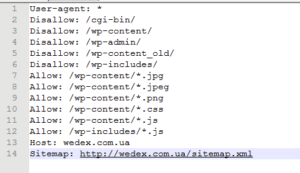
We do this with all files: styles – css and jpg, png images that you have on the site, you can also allow indexing of unique pdf, doc, xml, and other files if necessary. Let’s see what we ended up with. We check everything again to make sure we haven’t closed anything unnecessary, and move on.
Adding a link to the sitemap
This directive may not be necessary if you do not have a sitemap. But we still highly recommend generating site map, at least by an automatic service or created manually.
Add the Sitemap directive, put a colon and a space and insert a link to your sitemap. Our site map is in the root directory and has the standard name sitemap.xml. So, this is what we ended up with.
Adding a robots.txt file to the site
After you have finished compiling it, you need to add it to the site’s root folder. It’s very simple. This can be done through the program you used to look at the folders on ftp.
Just open the root folder of your site and drag the new robots there.
Checking in Google SearchConsole
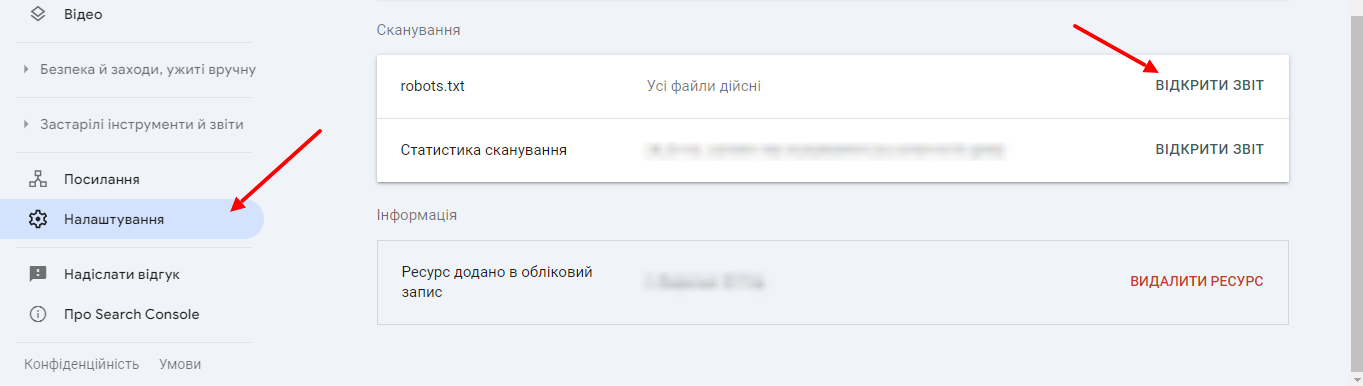
In GSC you can check whether Google can process your robots.txt files. To do this you need to open service under your login, click “Settings” – “Open report”.
Here you will see its parameters.
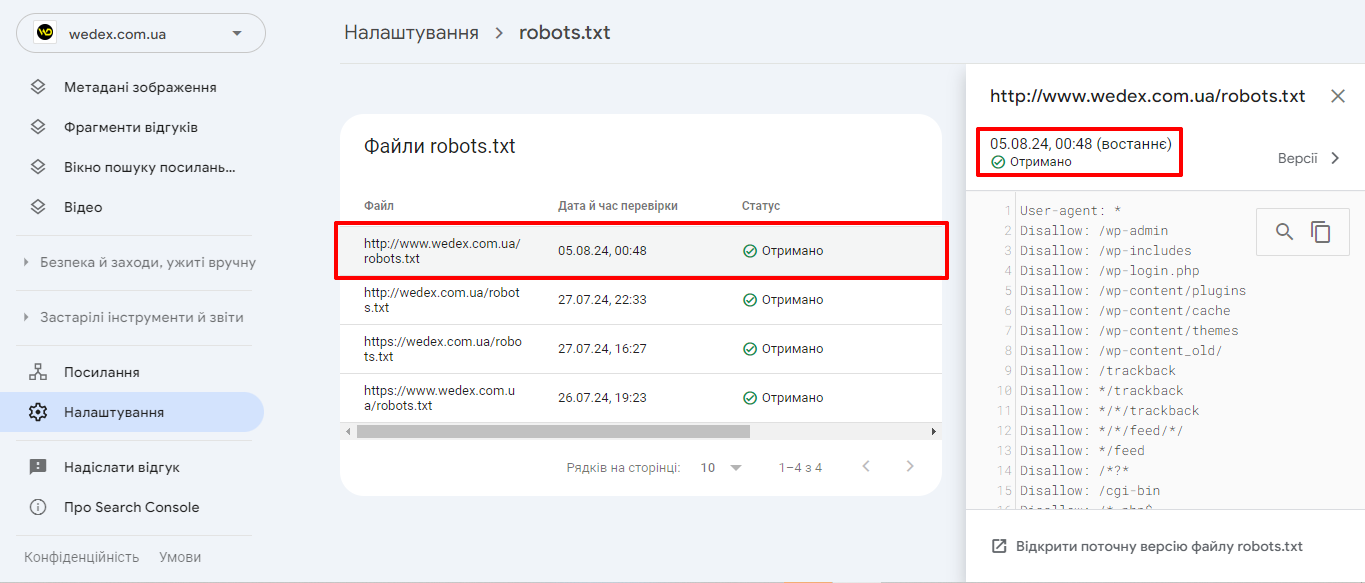
From the robots.txt report, you can see what robots.txt files Google found for the top 20 most popular hosts on your site, the last time they were crawled, and any warnings or errors.
To summarize
The robots.txt file is an important tool that plays a key role in interacting with search robots and is an integral part of effective SEO. It allows you to control the site indexing process and manage search engine access to certain pages. Correctly setting up robots.txt can significantly improve your site’s visibility in search results.

commercial offer
Other articles by the author

25/05/2024
Website indexing is the process of crawling a website by crawlers and adding it to the search engine database in a special form. Therefore, those pages that are in the search results are called indexed. This process is very important for the operation and promotion of the site.

18/09/2025
KPIs serve as a strategic tool for measuring results and improving business efficiency.

17/12/2025
A project roadmap is a high-level document. It reflects goals, key milestones, releases, and approximate deadlines, but does not detail daily tasks.
Latest articles by #SEO

16/06/2026
Performance marketing is an approach to promotion in which the primary goal is not abstract reach, but a specific and measurable result.

16/06/2026
Today, naming is a strategic tool that directly impacts customer acquisition cost (CAC), ad conversion rates, legal compliance, and, ultimately, a company’s market value.

15/06/2026
The algorithms of digital platforms are evolving faster than user habits, and by 2026, social media had undergone radical changes.